SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Résumé du communiqué de presse
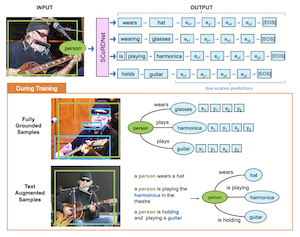
Des chercheurs de Rice University et d'Adobe Research ont mis au point un système appelé SCoRD — abréviation de Subject-Conditional Relation Detection — qui, étant donné un objet spécifique dans une photo, identifie automatiquement tout ce avec quoi cet objet interagit, en quoi consistent ces interactions et où se situent les autres objets dans l'image. Plutôt que d'essayer de cartographier toutes les relations possibles entre chaque objet d'une scène, ce qui devient vite impraticable, le système se concentre sur un seul sujet choisi et catalogue de manière exhaustive uniquement ses connexions pertinentes. L'équipe a conçu son modèle, SCoRDNet, comme un décodeur de séquences autorégressif qui produit des paires relation-objet ainsi que des coordonnées de boîtes englobantes sous forme d'un flux de jetons, et elle a conçu un banc d'essai fondé sur le jeu de données Open Images spécialement élaboré pour que les données d'entraînement et de test présentent des statistiques de relations discordantes — rendant plus difficile pour un modèle la simple mémorisation des motifs courants. Une conclusion clé est que les performances du système sur les types de relations rares ou jamais vus auparavant se sont nettement améliorées lorsque l'entraînement a été complété par des triplets de relations bruités automatiquement extraits de légendes d'images, même lorsque ces légendes ne comportaient aucune annotation de boîte englobante. Sur des relations que le modèle de base n'avait jamais rencontrées durant l'entraînement, la version augmentée par texte a atteint un rappel de 33,8% pour les paires relation-objet et de 26,75% pour leurs emplacements de boîtes, contre quasiment zéro pour la référence sans assistance. Ce travail est important car il offre une voie plus extensible vers la détection de relations à vocabulaire ouvert : plutôt que d'exiger des jeux de données coûteux entièrement annotés pour chaque interaction possible, l'approche suggère que de grandes collections d'images légendées déjà présentes sur Internet pourraient considérablement élargir ce que de tels systèmes peuvent reconnaître et localiser.
résumé
Nous proposons la détection de relations conditionnée au sujet (Subject-Conditional Relation Detection, SCoRD), où, conditionné par un sujet en entrée, l'objectif est de prédire toutes ses relations avec les autres objets d'une scène ainsi que leurs emplacements. À partir du jeu de données Open Images, nous proposons un banc d'essai exigeant, OIv6-SCoRD, tel que les partitions d'entraînement et de test présentent un décalage de distribution en matière de statistiques d'occurrence des triplets $\langle$sujet, relation, objet$\rangle$. Pour résoudre ce problème, nous proposons un modèle autorégressif qui, étant donné un sujet, prédit ses relations, ses objets et les emplacements des objets en exprimant cette sortie sous forme d'une séquence de jetons. Tout d'abord, nous montrons que les méthodes antérieures de prédiction de graphe de scène ne parviennent pas à produire une énumération aussi exhaustive de paires relation-objet lorsqu'elles sont conditionnées par un sujet sur ce banc d'essai. En particulier, nous obtenons un rappel@3 de 83,8% pour nos prédictions relation-objet, contre 49,75% obtenu par un détecteur de graphe de scène récent. Ensuite, nous montrons une meilleure généralisation à la fois sur les prédictions relation-objet et objet-boîte en exploitant durant l'entraînement des paires relation-objet obtenues automatiquement à partir de légendes textuelles et pour lesquelles aucune annotation objet-boîte n'est disponible. En particulier, pour les triplets $\langle$sujet, relation, objet$\rangle$ pour lesquels aucun emplacement d'objet n'est disponible durant l'entraînement, nous parvenons à obtenir un rappel@3 de 33,80% pour les paires relation-objet et de 26,75% pour leurs emplacements de boîtes.
détails
citation
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Qu'est-ce que SCoRD ? SCoRD est une tâche de détection de relations conditionnée au sujet où un modèle reçoit un sujet choisi dans une image et prédit les relations de ce sujet, les objets associés et les emplacements des objets.
- En quoi SCoRD diffère-t-il de la génération complète de graphe de scène ? Au lieu de prédire toutes les relations entre chaque objet, SCoRD se concentre sur la description exhaustive des relations d'un seul sujet interrogé, ce qui est souvent plus pratique pour les applications en aval.
- Qu'est-ce que SCoRDNet ? SCoRDNet est un modèle vision-langage autorégressif qui représente les prédictions relation-objet et les coordonnées de boîtes englobantes sous forme d'une séquence de jetons.
- Pourquoi utiliser des données augmentées par texte ? Les triplets relation-objet dérivés de légendes fournissent une supervision extensible pour les relations rares ou inédites, même lorsque les légendes ne comportent pas d'annotations de boîtes d'objets.
- Que teste le banc d'essai OIv6-SCoRD ? Le banc d'essai crée des décalages de distribution entre entraînement et test dans les triplets sujet-relation-objet, ce qui en fait un test exigeant de généralisation au-delà des statistiques de relations mémorisées.
Principales contributions
- L'article définit la détection de relations conditionnée au sujet comme une alternative ciblée à la génération complète de graphe de scène pour décrire les relations d'un objet spécifié.
- Il introduit OIv6-SCoRD, un banc d'essai conçu pour mettre à l'épreuve la détection de relations face à des décalages de distribution dans les statistiques relation-objet.
- SCoRDNet formule la prédiction de relation, d'objet et de localisation comme un problème unifié de décodage de jetons, permettant de gérer dans un seul modèle la supervision ancrée et non ancrée.
- L'article montre que l'entraînement augmenté par texte à partir de légendes améliore substantiellement la généralisation aux paires relation-objet sous-représentées et inédites.
- SCoRDNet surpasse les adaptations conditionnées au sujet des méthodes de graphe de scène sur la prédiction relation-objet et démontre que des légendes non ancrées peuvent améliorer à la fois la prédiction de relations et la localisation d'objets.
Limites et mises en garde
- SCoRD suppose qu'un sujet et sa boîte sont fournis en entrée, ce qui maintient la tâche ciblée et la rend bien adaptée aux applications où un utilisateur ou un détecteur en amont identifie l'objet d'intérêt.
- Les triplets de relations dérivés de légendes sont bruités et manquent souvent de boîtes d'objets, mais l'article transforme ce signal faible en atout en montrant qu'il améliore tout de même la généralisation lorsqu'il est combiné à des données ancrées.
- La méthode est évaluée sur un banc d'essai dérivé d'Open Images et de sources de légendes telles que COCO et Conceptual Captions, laissant des collections d'images en monde ouvert plus larges comme prochains tests naturels.
- SCoRDNet prédit les boîtes par décodage de séquences plutôt que par un raffinement de boîtes spécialisé, ce qui laisse de la place à de futures combinaisons avec des modules de localisation plus puissants.
- La tâche se concentre sur les relations centrées sur le sujet plutôt que sur des graphes de scène complets, offrant une formulation pratique et extensible tout en complétant les systèmes de génération de graphes plus larges.
Comment interpréter ce résultat
Cet article se lit au mieux comme une avancée solide vers une compréhension extensible des relations visuelles : SCoRD reformule la détection de relations autour d'un sujet interrogé, et SCoRDNet montre qu'une supervision peu coûteuse par légendes peut élargir de manière significative les paires relation-objet qu'un modèle peut reconnaître et localiser.