One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Sintesi del comunicato stampa
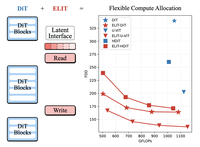
I ricercatori della Rice University e di Snap Inc. hanno sviluppato una tecnica chiamata ELIT, abbreviazione di Elastic Latent Interface Transformer, che dà ai modelli di generazione di immagini e video la capacità di bilanciare al volo la velocità di calcolo rispetto alla qualità dell'output — senza riaddestrare il modello per ciascun punto operativo desiderato. Il problema centrale che hanno affrontato è che i modelli diffusion transformer standard impiegano la stessa quantità di calcolo su ogni patch di un'immagine, indipendentemente dal fatto che quella patch contenga dettagli intricati o cielo vuoto, e sono vincolati a un costo computazionale fisso legato alla risoluzione dell'immagine. Per risolvere questo problema, il team ha inserito un piccolo insieme di "token latenti" apprendibili tra le fasi di elaborazione iniziali e finali del modello, collegati da due leggeri layer di cross-attention che chiamano Read e Write. Durante l'addestramento, il modello elimina casualmente alcuni di quei token latenti, il che lo costringe a concentrare le informazioni più importanti nei token che conserva più spesso, producendo una rappresentazione naturalmente ordinata. In fase di inferenza, un utente può semplicemente scegliere quanti token latenti utilizzare, regolando direttamente il calcolo verso l'alto o verso il basso. Testato su diverse architetture popolari tra cui DiT, U-ViT, HDiT e il modello Qwen-Image da 20 miliardi di parametri, ELIT ha migliorato in modo costante le metriche di qualità delle immagini — riducendo i punteggi FID fino al 53% sui benchmark ImageNet a 512 pixel — consentendo al contempo agli utenti di ridurre il calcolo di circa il 35-65% con una perdita di qualità solo modesta. L'approccio sblocca inoltre una forma più economica di classifier-free guidance utilizzando la versione a basso numero di token dello stesso modello come riferimento "debole" integrato, riducendo i costi di guidance di circa un terzo.
abstract
I diffusion transformer (DiT) raggiungono un'elevata qualità generativa ma vincolano i FLOP alla risoluzione dell'immagine, limitando compromessi di principio tra latenza e qualità, e allocano il calcolo in modo uniforme tra i token spaziali di input, sprecando l'allocazione delle risorse su regioni poco importanti. Introduciamo Elastic Latent Interface Transformer (ELIT), un meccanismo drop-in e compatibile con i DiT che disaccoppia la dimensione dell'immagine di input dal calcolo. Il nostro approccio inserisce un'interfaccia latente, una sequenza di token apprendibile e di lunghezza variabile su cui possono operare i normali blocchi transformer. Leggeri layer di cross-attention Read e Write spostano le informazioni tra i token spaziali e i latenti e danno priorità alle regioni di input importanti. Addestrando con l'eliminazione casuale dei latenti finali, ELIT impara a produrre rappresentazioni ordinate per importanza, in cui i latenti iniziali catturano la struttura globale mentre quelli successivi contengono informazioni per rifinire i dettagli. In fase di inferenza, il numero di latenti può essere regolato dinamicamente per adattarsi ai vincoli di calcolo. ELIT è deliberatamente minimale, aggiungendo due layer di cross-attention pur lasciando invariati l'obiettivo di rectified flow e lo stack DiT. Su diversi dataset e architetture (DiT, U-ViT, HDiT, MM-DiT), ELIT offre guadagni costanti. Su ImageNet-1K 512px, ELIT offre un guadagno medio del $35,3\%$ e del $39,6\%$ nei punteggi FID e FDD. Pagina del progetto: https://snap-research.github.io/elit/
dettagli
citazione
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Che cos'è ELIT e quale problema affronta? ELIT è un meccanismo a interfaccia latente drop-in per i diffusion transformer che disaccoppia il calcolo dalla risoluzione dell'immagine e consente a un singolo modello generativo di operare con molteplici budget di qualità e latenza.
- Come modifica ELIT un diffusion transformer? Inserisce un insieme di token latenti di lunghezza variabile tra una breve testa e una breve coda spaziali, utilizzando leggeri layer di cross-attention Read e Write per spostare le informazioni tra i token dell'immagine e l'interfaccia latente.
- Come fornisce ELIT budget di inferenza flessibili? Durante l'addestramento, i token latenti finali vengono eliminati casualmente in modo che i token iniziali apprendano le informazioni più importanti, e in fase di inferenza gli utenti scelgono quanti token latenti conservare per controllare i FLOP.
- Quali guadagni empirici riporta ELIT? Su ImageNet-1K 512px, ELIT migliora sostanzialmente FID e FDD su backbone DiT, U-ViT e HDiT, incluso un miglioramento di FID fino al 53 percento per la configurazione DiT riportata nell'articolo.
- ELIT scala a grandi modelli di generazione? Sì, l'articolo applica ELIT a Qwen-Image, un modello MM-DiT da 20B, e mostra un fluido compromesso tra calcolo e qualità con uno speedup fino a circa 2,7x mantenendo al contempo solidi punteggi DPG-Bench.
Principali contributi
- L'articolo introduce un'interfaccia latente Read/Write minimale che mantiene invariati l'obiettivo di rectified flow e lo stack DiT principale, rendendo ELIT facile da innestare sulle famiglie di diffusion transformer esistenti.
- ELIT dimostra un calcolo adattivo utilizzando il layer Read per attirare le regioni spaziali informative nell'interfaccia latente anziché spendere lo stesso calcolo su regioni facili o riempite di padding.
- La strategia di addestramento multi-budget crea una sequenza latente ordinata per importanza, consentendo a un singolo insieme di pesi di supportare molti budget di inferenza senza riaddestramento.
- Gli esperimenti mostrano miglioramenti costanti nella generazione di immagini su DiT, U-ViT e HDiT, risultati favorevoli nella generazione di video su Kinetics-700 e compatibilità con metodi di accelerazione privi di addestramento come TeaCache.
- ELIT abilita una guidance e un'autoguidance economiche utilizzando versioni a budget inferiore dello stesso modello come riferimenti deboli, riducendo il costo della guidance e migliorando al contempo la qualità dei campioni.
Limiti e avvertenze
- ELIT aggiunge i layer Read e Write più lo scheduling dei token latenti, perciò è una piccola modifica architetturale anziché un metodo di accelerazione puramente privo di addestramento; il design drop-in e i risultati su un'ampia gamma di backbone giustificano bene quella complessità aggiuntiva.
- L'esperimento su Qwen-Image effettua il fine-tuning di un grande modello esistente con dati reali e sintetici disponibili anziché riprodurre l'intera pipeline di addestramento proprietaria del modello originale, ma fornisce comunque preziose evidenze del fatto che ELIT scala a sistemi MM-DiT da 20B parametri.
- Le configurazioni di Qwen-Image a budget più basso sacrificano un po' di qualità sui benchmark in cambio di velocità, cosa attesa per un modello elastico e utile perché gli utenti possono scegliere il budget più adatto alle loro esigenze di latenza e qualità.
- La maggior parte delle ablazioni dettagliate riguarda configurazioni di ImageNet class-conditional e Kinetics, lasciando i dettagli di implementazione text-to-image e le preferenze di qualità per l'utente come naturali direzioni di valutazione future.
- Il metodo migliora l'allocazione del calcolo all'interno dei generatori di tipo DiT anziché sostituire tutte le altre tecniche di efficienza, e la compatibilità con TeaCache e le strategie di guidance suggerisce che possa essere combinato in modo produttivo con acceleratori complementari.
Come interpretare questo risultato
Questo articolo è meglio interpretato come un solido contributo di sistemi e modellazione per i diffusion transformer: ELIT dà a un singolo modello un controllo pratico sui budget di calcolo, migliora la qualità della generazione su diversi backbone e scala l'idea a grandi generatori di immagini moderni mantenendo al contempo compatte le modifiche all'architettura di base.