Grounding Language Models for Visual Entity Recognition
Sintesi del comunicato stampa
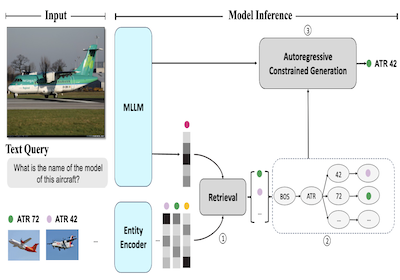
I ricercatori della Rice University e di Microsoft hanno sviluppato un sistema chiamato AutoVER che migliora drasticamente la capacità di un computer di identificare specifiche entità del mondo reale nelle immagini — si pensi alla distinzione di un particolare modello di aereo da un altro quasi identico — ancorando le ipotesi di un modello linguistico di IA a una concreta base di conoscenza anziché lasciargli generare qualunque risposta sembri plausibile. Il problema centrale è che i sistemi di IA multimodali esistenti, che elaborano sia immagini sia testo, tendono ad allucinare o a produrre risposte al livello di specificità sbagliato quando vengono poste domande di riconoscimento a grana fine, come stabilire se un velivolo raffigurato sia un ATR 42 o un British Aerospace 146. AutoVER affronta questo problema combinando due tecniche: addestra il modello a recuperare entità candidate visivamente e semanticamente simili da un database di oltre sei milioni di voci di Wikipedia utilizzando un approccio di contrastive learning, e poi, durante la generazione della risposta, restringe l'output del modello soltanto a quei candidati recuperati costruendo un prefix tree che blocca qualsiasi sequenza di token che porterebbe a risposte non valide. Il sistema è stato testato sul benchmark Oven-Wiki, un dataset su larga scala progettato specificamente per questo tipo di sfida di visual entity recognition, dove ha portato l'accuratezza sulle entità che il modello aveva visto in addestramento da circa il 32.7 percento al 61.5 percento, superando al contempo modelli molto più grandi come PaLI-17B di Google su esempi che coinvolgono entità mai viste e domande che richiedono ragionamento visivo. Il lavoro è importante perché un riconoscimento affidabile delle entità a partire dalle immagini ha applicazioni pratiche in ambiti che vanno dai motori di ricerca agli strumenti di accessibilità, e l'approccio dimostra che accoppiare strettamente il retrieval con la generazione vincolata è un percorso più affidabile rispetto a ingrandire semplicemente un modello sperando che azzecchi risposte sufficientemente specifiche.
abstract
Introduciamo AutoVER, un modello Autoregressive per il Visual Entity Recognition. Il nostro modello estende un Multi-modal Large Language Model autoregressivo impiegando la retrieval augmented constrained generation. Mitiga le basse prestazioni sulle entità out-of-domain pur eccellendo nelle query che richiedono un ragionamento situato visivamente. Il nostro metodo impara a distinguere entità simili all'interno di uno spazio di etichette molto vasto addestrandosi in modo contrastive su coppie di hard negative in parallelo con un obiettivo sequence-to-sequence, senza un retriever esterno. Durante l'inferenza, un elenco di risposte candidate recuperate guida esplicitamente la generazione del linguaggio rimuovendo i percorsi di decoding non validi. Il metodo proposto ottiene miglioramenti significativi su diversi split del dataset nel recentemente proposto benchmark Oven-Wiki. L'accuratezza sullo split Entity seen sale dal 32.7% al 61.5%. Dimostra inoltre prestazioni superiori sugli split unseen e query con un margine sostanziale a due cifre.
dettagli
citazione
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Che cos'è AutoVER? AutoVER è un modello linguistico multimodale autoregressivo per il visual entity recognition, in cui le risposte devono essere ancorate a entità specifiche all'interno di una vasta base di conoscenza.
- Quale problema affronta il paper? Affronta il riconoscimento di entità a grana fine basato su immagini, in cui i modelli devono distinguere entità visivamente simili ed evitare di allucinare risposte al di fuori dello spazio valido di entità.
- Come funziona qui la retrieval-augmented constrained generation? AutoVER recupera le entità probabili, costruisce un prefix tree dinamico a partire da quei candidati e vincola il decoding in modo che la generazione segua solo percorsi di token di nomi di entità validi.
- Perché usare il contrastive learning e gli hard negative? Il modello apprende il retrieval da query a entità con hard negative simili visivamente e nella conoscenza, aiutandolo a separare entità che condividono aspetto o struttura categoriale.
- Dove viene valutato AutoVER? Il paper valuta su Oven-Wiki e testa anche il transfer zero-shot su un sottoinsieme di A-OKVQA ancorato alle entità.
Principali contributi
- Il paper introduce AutoVER, un framework autoregressivo retrieval-augmented per ancorare gli output di un modello linguistico multimodale a entità visive su scala Wikipedia.
- Integra l'addestramento contrastive da query a entità direttamente nel modello linguistico multimodale, evitando la dipendenza da un retriever esterno separato.
- Il meccanismo di decoding vincolato garantisce che le risposte generate siano ancorate alle entità candidate recuperate, riducendo direttamente le generazioni non valide o non ancorate.
- Il hard-negative mining basato sulla somiglianza visiva e sulla gerarchia della base di conoscenza migliora la discriminazione a grana fine tra entità visivamente simili.
- AutoVER migliora sostanzialmente le prestazioni su Oven-Wiki, inclusi l'aumento dell'accuratezza Entity seen dal 32.7% al 61.5% nel confronto riportato e il superamento di baseline PaLI più grandi sugli split unseen e query.
Limiti e avvertenze
- AutoVER dipende dalla copertura e dalla qualità della base di conoscenza delle entità, cosa appropriata per il visual entity recognition e che rende esplicito l'obiettivo di grounding.
- Il metodo recupera un insieme di candidati prima del decoding vincolato, quindi le entità molto rare o visivamente ambigue rimangono impegnative quando il retrieval le manca; il paper affronta direttamente questo aspetto con feature visive sul lato entità e addestramento con hard negative.
- L'addestramento su scala Wikipedia richiede dati e capacità di calcolo considerevoli, ma il risultato è un framework pratico per trasformare grandi basi di conoscenza in obiettivi di riconoscimento visivo utilizzabili.
- Il paper mostra ancora un divario rispetto alle prestazioni di umano più ricerca sul set di valutazione umana, il che costituisce un utile benchmark per i progressi futuri piuttosto che una debolezza dell'approccio di base.
- AutoVER è specializzato per risposte ancorate alle entità, complementando i più ampi sistemi di VQA open-ended quando l'output desiderato dovrebbe essere un'entità nominata precisa.
Come interpretare questo risultato
Questo paper si legge al meglio come un solido contributo al riconoscimento multimodale ancorato: AutoVER mostra che il retrieval, l'apprendimento contrastive delle entità e la generazione vincolata possono rendere le risposte di un modello linguistico molto più precise e affidabili per il visual entity recognition su scala Wikipedia.