ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
プレスリリース要約
ライス大学とGoogle DeepMindの研究者らは、ラベル付きデータを必要とせずに、単一のAIモデルが静止画像と動画の両方を理解するように訓練する、ViC-MAEと呼ばれる自己教師あり視覚学習システムを開発しました。彼らが取り組んだ中心的な課題は、既存のモデルが一方のモダリティには強くてももう一方には強くない傾向があること、そして特に動画で訓練されたモデルが画像タスクで高い性能を求められたときに従来から苦戦してきたことです。彼らのアプローチは、既存の2つの技術を組み合わせています。1つは、画像のランダムに隠されたパッチを再構成するようモデルを訓練するマスク付きオートエンコーダ、もう1つは、同じシーンの2つの異なるビューが類似した表現を生成すべきだとモデルに認識させるよう訓練する対照学習です。新しい工夫は、フレームを繰り返すことで画像を擬似的な動画に人工的に変換するという一般的な回避策の代わりに、ViC-MAEが実際の動画内で1秒ほど離れてサンプリングされたフレームを、同じシーンの自然な「拡張ビュー」として扱う点にあります。こうした時間的な変化を対照学習の目的に取り込みつつ、マスキング損失で個々のフレームの再構成も行います。研究チームはまた、単一の分類トークンに頼るのではなく、局所的なパッチ特徴を大域表現にプーリングすることが、訓練中のモデルの崩壊を防ぐのに役立つことも発見しました。標準的なベンチマークでテストした結果、ViC-MAEのViT-Largeバージョンは、ImageNetでtop-1精度87.1%、難易度の高いSomething-Something-v2動画ベンチマークで75.9%に達し、同等の自己教師あり手法であるOmniMAEをImageNetで約2.4パーセントポイント上回るとともに、動画タスクでも上回りました。これは、動画データを慎重に用いれば、動画の性能を犠牲にすることなく画像理解を有意に強化できることを示唆する結果です。
要旨
私たちは、マスク付きオートエンコーダ(MAE)と対照学習の両方を組み合わせたモデルであるViC-MAEを提案します。ViC-MAEは、MAEの再構成損失のもとで学習された局所表現をプーリングして得られる大域特徴を用いて訓練され、この表現を画像と動画フレームにわたる対照目的のもとで活用します。私たちは、ViC-MAEのもとで学習された視覚表現が、動画と画像の両方の分類タスクにうまく汎化することを示します。特にViC-MAEは、最近提案されたOmniMAEと比較して、同一データで訓練した場合にtop-1精度86%(絶対値で+1.3%の改善)を、追加データで訓練した場合に87.1%(絶対値で+2.4%の改善)を達成し、動画から画像へのImagenet-1kにおける最先端の転移学習性能を獲得します。同時にViC-MAEは、難易度の高いSomething-Something-v2動画ベンチマークでtop-1精度75.9%を獲得し、動画ベンチマークにおいて他のほとんどの手法を上回ります。多様なデータセットの組み合わせから得た動画と画像で訓練した場合、私たちの手法は動画分類と画像分類のベンチマーク間でバランスの取れた転移学習性能を維持し、最良の教師あり手法にわずかな差で次ぐ結果となります。
詳細
引用
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- ViC-MAEとは何ですか。ViC-MAEは、マスク付きオートエンコーディングと対照学習を組み合わせた自己教師あり視覚表現学習の手法で、1つのバックボーンが画像と動画の両方に有用な特徴を学習できるようにします。
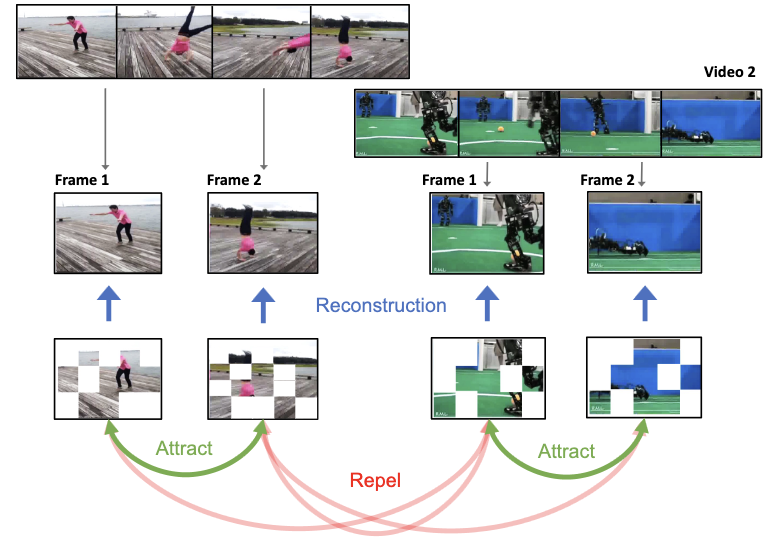
- ViC-MAEは従来の画像・動画事前学習手法と動画の使い方がどう異なりますか。画像をフレーム繰り返しの動画に変換する代わりに、ViC-MAEは実際の動画から得た近接フレームを自然な時間的拡張として扱い、それらのプーリングされた表現を整合させます。
- マスク付き画像モデリングと対照学習をなぜ組み合わせるのですか。再構成目的は強力な局所パッチ特徴を促し、対照目的は拡張された画像と時間的にずれた動画フレームにわたる大域的な不変性を促します。
- この手法においてプーリングはどのような役割を果たしますか。ViC-MAEは対照ブランチの前に局所的なViT特徴を大域表現にプーリングします。この論文は、これが安定した訓練に重要であり、分類トークンだけに頼ることを避けられることを示しています。
- ViC-MAEがバランスの取れた画像表現と動画表現を学習するという証拠は何ですか。この論文は、ImageNet、Kinetics-400、Places365、Something-Something-v2、いくつかの下流の画像分類データセット、そしてCOCOの検出とセグメンテーションへの強力な転移を報告しています。
主な貢献
- この論文は、マスク付き再構成と対照的な整合の組み合わせを用いて、画像と動画の両方から訓練する統一的な自己教師ありフレームワークを導入しています。
- ViC-MAEは、動画フレームが画像レベルの表現学習に有効な時間的拡張として機能し、動画の性能を犠牲にすることなく動画から画像への転移を改善できることを示しています。
- この手法は、局所的なMAE特徴に対する大域プーリングを、安定した対照的マスク付きオートエンコーダの訓練のための実用的な設計選択として特定しています。
- ViT-Largeバックボーンを用いて、ViC-MAEはImageNetのtop-1精度87.1%とSomething-Something-v2のtop-1精度75.9%に達し、報告された設定においてOmniMAEのような同等の自己教師ありベースラインを上回ります。
- この論文は、画像分類、動画の行動認識、物体検出、セグメンテーションにわたる幅広い実証的検証を提供しており、その貢献を単一のベンチマークを超えて有用なものにしています。
限界と注意点
- 最も強力な結果は大規模なViTバックボーンと複数データセットでの事前学習を用いており、これは現代の基盤モデル型の視覚表現学習では一般的であり、この手法のスケーリング挙動を示すのに役立ちます。
- ViC-MAEは、考えうるあらゆる下流の動画・画像タスクではなく、主に転移とファインチューニングのベンチマークを通じて評価されており、追加のドメインを有望な追跡評価として残しています。
- このアプローチは再構成目的と対照目的の慎重なバランスに依存しますが、この論文にはプーリング、フレーム間隔、拡張、データの混合に関するアブレーションが含まれており、設計上の選択を明確にしています。
- この手法は統一的な画像・動画の自己教師あり学習を改善する一方、タスク固有の教師ありモデルは個々のベンチマークによっては依然として競争力を持ちます。これはViC-MAEを、狭い専門家ではなく強力な汎用表現学習器として位置づけるものです。
- この論文は視覚のみの事前学習に焦点を当てているため、テキスト、音声、あるいはより広範なマルチモーダル整合への拡張は、同じフレームワークを土台とする自然な機会として残されています。
この結果の読み解き方
この論文は、自己教師あり画像・動画表現学習における力強く実用的な進歩として読むのが最適です。ViC-MAEは、優れた動画性能を保ちながら動画データが画像表現を改善できることを実証しており、しかもそれをマスク付きオートエンコーディング、時間的対照学習、プーリングされた局所特徴の洗練された組み合わせによって実現しています。