プレスリリース要約
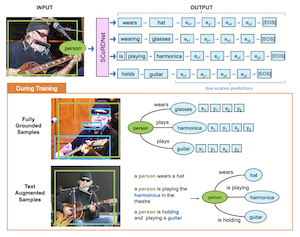
ライス大学とAdobe Researchの研究者らは、SCoRD(Subject-Conditional Relation Detection、主語条件付き関係検出の略)と呼ばれるシステムを開発しました。これは、写真内の特定の物体が与えられると、その物体が相互作用しているすべての対象、それらの相互作用がどのようなものか、そして画像内で他の物体がどこに位置しているかを自動的に識別するものです。すぐに非現実的になってしまう、シーン内のあらゆる物体間のあらゆる可能な関係を対応づけようとするのではなく、このシステムは選ばれた1つの主語に焦点を当て、その関連するつながりのみを網羅的に目録化します。研究チームは、自分たちのモデルSCoRDNetを、関係・目的語のペアをバウンディングボックス座標とともにトークンの流れとして出力する自己回帰的なシーケンスデコーダとして構築し、訓練データとテストデータの関係統計が不一致になるよう特別に作られたOpen Imagesデータセットに基づくベンチマークを設計しました。これにより、モデルが一般的なパターンを単に記憶することが難しくなります。重要な発見は、たとえそれらのキャプションにバウンディングボックスアノテーションが一切付いていなくても、画像キャプションから自動抽出されたノイズの多い関係三つ組を訓練に補ったとき、稀な、または以前に見たことのない関係タイプに対するシステムの性能が大幅に改善されたことです。ベースモデルが訓練中に一度も遭遇しなかった関係について、テキスト拡張版は、補助なしのベースラインのほぼゼロと比較して、関係・目的語のペアで33.8%、それらのボックス位置で26.75%の再現率を達成しました。この研究が重要なのは、オープン語彙の関係検出に向けたよりスケーラブルな道筋を提供するからです。すなわち、あらゆる可能な相互作用について高価な完全アノテーション付きデータセットを必要とするのではなく、このアプローチは、インターネット上にすでに存在するキャプション付き画像の大規模なコレクションが、こうしたシステムが認識・位置特定できる対象を劇的に拡張しうることを示唆しています。
要旨
私たちは、入力された主語を条件として、その主語がシーン内の他の物体に対して持つすべての関係を、それらの位置とともに予測することを目標とする、主語条件付き関係検出(Subject-Conditional Relation Detection、SCoRD)を提案します。Open Imagesデータセットに基づき、私たちは、訓練分割とテスト分割が$\langle$主語, 関係, 目的語$\rangle$の三つ組の出現統計の点で分布シフトを持つような、難易度の高いOIv6-SCoRDベンチマークを提案します。この問題を解決するため、私たちは、主語が与えられると、その出力をトークン列として表現することで、その関係、目的語、目的語の位置を予測する自己回帰モデルを提案します。まず、このベンチマークにおいて主語を条件とした場合、従来のシーングラフ予測手法が、関係と目的語のペアをこれほど網羅的に列挙できないことを示します。特に私たちは、最近のシーングラフ検出器が得た49.75%と比較して、関係・目的語予測でrecall@3が83.8%を獲得します。次に、テキストキャプションから自動的に得られ、目的語のボックスアノテーションが利用できない関係・目的語のペアを訓練中に活用することで、関係・目的語と目的語ボックスの両方の予測において汎化が改善されることを示します。特に、訓練中に目的語の位置が利用できない$\langle$主語, 関係, 目的語$\rangle$の三つ組について、私たちは関係・目的語のペアでrecall@3が33.80%、それらのボックス位置で26.75%を獲得できます。
詳細
引用
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- SCoRDとは何ですか。SCoRDは主語条件付き関係検出タスクであり、モデルは画像内の選ばれた主語を受け取り、その主語の関係、関連する物体、物体の位置を予測します。
- SCoRDは完全なシーングラフ生成とどう異なりますか。あらゆる物体間のあらゆる関係を予測するのではなく、SCoRDはクエリされた1つの主語の関係を網羅的に記述することに焦点を当てており、これは下流の応用にとってしばしばより実用的です。
- SCoRDNetとは何ですか。SCoRDNetは、関係・目的語の予測とバウンディングボックス座標をトークンの列として表現する自己回帰型の視覚言語モデルです。
- なぜテキスト拡張データを用いるのですか。キャプション由来の関係・目的語の三つ組は、キャプションに物体ボックスアノテーションが含まれていない場合でも、稀な、または未知の関係に対するスケーラブルな教師を提供します。
- OIv6-SCoRDベンチマークは何をテストしますか。このベンチマークは主語・関係・目的語の三つ組において訓練・テスト間の分布シフトを作り出し、記憶された関係統計を超えた汎化の強力なテストとなります。
主な貢献
- この論文は、指定された物体の関係を記述するための、完全なシーングラフ生成に代わる的を絞った手法として、主語条件付き関係検出を定義しています。
- 関係・目的語の統計における分布シフトのもとで関係検出をストレステストするよう設計されたベンチマークである、OIv6-SCoRDを導入しています。
- SCoRDNetは、関係、目的語、位置特定の予測を統一的なトークンデコード問題として表現し、グラウンディングありとなしの教師を1つのモデルで扱えるようにしています。
- この論文は、キャプションからのテキスト拡張訓練が、過小に表現された、または未知の関係・目的語のペアへの汎化を大幅に改善することを示しています。
- SCoRDNetは、関係・目的語の予測において、シーングラフ手法を主語条件付きに適応させたものを上回り、グラウンディングされていないキャプションが関係予測と物体位置特定の両方を改善できることを実証しています。
限界と注意点
- SCoRDは主語とそのボックスが入力として与えられることを前提としており、これによりタスクが的を絞ったものとなり、ユーザーや上流の検出器が関心のある物体を特定するアプリケーションによく適しています。
- キャプション由来の関係三つ組はノイズが多く、しばしば物体ボックスを欠いていますが、この論文は、グラウンディングされたデータと組み合わせたときに依然として汎化を改善することを示すことで、この弱い信号を強みに変えています。
- この手法は、Open ImagesとCOCOやConceptual Captionsといったキャプションソースから得られたベンチマークで評価されており、より広範なオープンワールドの画像コレクションを自然な次のテストとして残しています。
- SCoRDNetは専用のボックス精緻化ではなくシーケンスデコードを通じてボックスを予測するため、より強力な位置特定モジュールとの将来的な組み合わせの余地を残しています。
- このタスクは完全なシーングラフではなく主語中心の関係に焦点を当てており、より広範なグラフ生成システムを補完しつつ、実用的でスケーラブルな定式化を提供します。
この結果の読み解き方
この論文は、スケーラブルな視覚的関係理解に向けた力強い一歩として読むのが最適です。SCoRDは関係検出をクエリされた主語を中心に再構成し、SCoRDNetは、安価なキャプションの教師が、モデルが認識・位置特定できる関係・目的語のペアを有意に拡張できることを示しています。