Improving Progressive Generation with Decomposable Flow Matching
보도 자료 요약
라이스 대학교와 Snap Inc.의 연구자들은 다단계 생성 시스템에 흔히 수반되는 복잡성 없이 품질을 향상시키는, 고해상도 이미지와 비디오를 생성하는 새로운 접근법을 개발했다. Decomposable Flow Matching(DFM)이라 불리는 이 연구는 AI 이미지 합성의 알려진 난제를 다룬다. 즉, 정교한 시각적 세부를 효율적으로 생성하려면 작업을 거친 단계에서 세밀한 단계로 쪼개야 하지만, 이를 수행하는 기존 방법은 보통 각 단계마다 별도의 모델, 맞춤형 디퓨전 과정, 또는 단계 간의 정교한 인계를 요구한다. DFM은 단일 공유 모델을 전반에 걸쳐 사용하면서 다중 스케일 이미지 표현, 즉 본질적으로 이미지를 점점 더 세밀한 세부의 계층으로 분리하는 Laplacian pyramid의 각 수준에 Flow Matching이라는 표준 기법을 독립적으로 적용함으로써 이러한 복잡성을 우회한다. 학습 중에 시스템은 각 단계마다 서로 다른 노이즈 수준을 샘플링하여 점진적 생성 과정을 모사하며, 추론 시에는 간단한 스케줄러가 거친 단계에서 세밀한 단계로 순차적으로 단계를 이동한다. 512픽셀 해상도의 표준 ImageNet-1K 벤치마크에서 시험한 결과, DFM은 동일한 양의 학습 연산을 사용하여 FDD라는 핵심 품질 지표를 일반 Flow Matching 대비 35%, 가장 우수한 경쟁 다단계 방법 대비 26% 감소시켰다. 연구자들은 또한 DFM을 대형 상용급 이미지 생성 모델인 FLUX의 미세조정에 적용하여, 표준 미세조정보다 목표 이미지 분포로 더 빠르게 수렴하며 FID 점수를 대략 29% 낮추는 것을 확인했다. 이 연구의 의의는 주로 단순성에 있다. 즉, 완전히 새로운 아키텍처나 별도의 모델 캐스케이드를 요구하는 대신 기존 학습 파이프라인에 대한 최소한의 수정을 통해 유의미한 품질 향상을 제공한다.
초록
고차원 시각 양식(visual modality)을 생성하는 것은 연산 집약적인 작업이다. 흔한 해결책은 점진적 생성(progressive generation)으로, 출력물을 거친 단계에서 세밀한 단계로 향하는 스펙트럼 자기회귀(spectral autoregressive) 방식으로 합성한다. 디퓨전 모델은 디노이징의 거친-에서-세밀한 특성으로부터 이점을 얻지만, 명시적인 다단계 아키텍처는 거의 채택되지 않는다. 이러한 아키텍처는 전체 접근법의 복잡성을 높여, 맞춤형 디퓨전 정식화, 분해에 의존적인 단계 전환, 임시방편적 샘플러, 또는 모델 캐스케이드의 필요성을 야기했다. 우리의 기여인 Decomposable Flow Matching(DFM)은 시각 매체의 점진적 생성을 위한 간단하고 효과적인 프레임워크이다. DFM은 사용자가 정의한 다중 스케일 표현(예: Laplacian pyramid)의 각 수준에서 Flow Matching을 독립적으로 적용한다. 우리의 실험이 보여주듯, 우리의 접근법은 이미지와 비디오 모두에 대해 시각 품질을 향상시키며 이전 다단계 프레임워크 대비 우수한 결과를 보인다. Imagenet-1k 512px에서, DFM은 동일한 학습 연산량 하에서 FDD 점수 기준으로 기본 아키텍처 대비 35.2%, 가장 성능이 좋은 베이스라인 대비 26.4%의 향상을 달성한다. FLUX와 같은 대형 모델의 미세조정에 적용했을 때, DFM은 학습 분포로의 더 빠른 수렴 속도를 보인다. 결정적으로, 이 모든 이점은 단일 모델, 아키텍처의 단순성, 그리고 기존 학습 파이프라인에 대한 최소한의 수정으로 달성된다.
세부 정보
인용
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
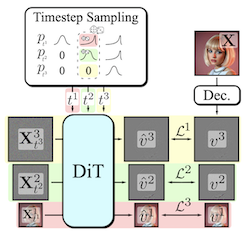
- Decomposable Flow Matching이란 무엇이며 어떤 문제를 다루는가? DFM은 다중 스케일 표현의 각 수준에 걸쳐 Flow Matching을 독립적으로 적용하는 점진적 생성 프레임워크로, 모델 캐스케이드나 맞춤형 디퓨전 과정을 요구하지 않으면서 거친-에서-세밀한 이미지 및 비디오 합성을 향상시킨다.
- DFM은 샘플을 어떻게 점진적으로 생성하는가? DFM은 시각 데이터를 Laplacian pyramid와 같은 단계로 분해하고, 각 단계에 고유한 flow 타임스텝을 할당하며, 거친 구조에서 세밀한 세부로 단계를 전진시키는 샘플러를 사용한다.
- DFM은 왜 많은 기존 점진적 생성 방법보다 단순한가? DFM은 단일 공유 모델과 표준 Flow Matching 정식화를 유지하여, 단계별 개별 모델, 특수 샘플러, 복잡한 전환 메커니즘을 피한다.
- DFM은 이미지 생성 벤치마크에서 어떤 성능을 보이는가? 512px 및 1024px의 ImageNet-1K에서 DFM은 논문에서 보고된 주요 지표와 guidance 설정 전반에 걸쳐 Flow Matching, 캐스케이드 베이스라인, Pyramidal Flow를 능가한다.
- DFM은 대규모 모델 미세조정에 도움이 되는가? 그렇다. FLUX 미세조정에 적용했을 때, DFM은 동일한 학습 연산량 하에서 표준 미세조정보다 더 나은 FID, FDD, CLIP 유사도에 도달하여, 목표 분포로의 더 빠른 수렴을 보인다.
주요 기여
- 본 논문은 단일 공유 생성기를 유지하면서 시각 생성을 분해 가능한 거친-에서-세밀한 과정으로 전환하는, Flow Matching의 간단한 다중 스케일 확장을 도입한다.
- DFM은 사용자가 정의한 분해를 지원하며, 본 논문은 Laplacian pyramid를 사용하면서도 wavelet, DCT, Fourier, 또는 다중 스케일 오토인코더 분해가 자연스러운 대안임을 언급한다.
- 이 방법은 학습 타임스텝 분포, 샘플링 임계값, 단계별 샘플링 스텝, 마스킹, 분해 선택, 연산 할당 전략에 대한 상세한 분석을 포함한다.
- 실험은 ImageNet-1K 이미지 생성과 Kinetics-700 비디오 생성에서 강력한 결과를 보이며, 대부분의 설정에서 논문의 점진적 생성 베이스라인 가운데 가장 우수하게 보고된 값을 포함한다.
- FLUX 미세조정 실험은 DFM이 학습 파이프라인에 대한 최소한의 변경만으로 대형 생성 모델의 적응을 향상시킬 수 있음을 입증한다.
한계 및 유의 사항
- DFM은 추가적인 학습 및 샘플링 하이퍼파라미터를 도입하지만, 본 논문은 안정적인 설정이 여러 실험에 걸쳐 이전됨을 보이는 광범위한 절제 실험과 실용적 지침을 제공한다.
- 이 프레임워크의 성능은 저주파 구조와 고주파 세부의 균형에 의존하므로 향후 연구가 자동 스케줄링 정책을 정교화할 수 있는데, 현재 결과는 이미 이 균형이 큰 품질 향상을 낳을 수 있음을 보인다.
- 주된 구현은 Laplacian 분해를 사용하여, DCT, wavelet, 다중 스케일 오토인코더와 같은 다른 분해는 핵심 정식화의 약점이라기보다는 유망한 확장으로 남겨둔다.
- 대형 모델 실험은 모든 배치 설정에서 원본 프런티어 모델을 개선한다고 주장하기보다는 FLUX를 목표 분포로 미세조정하는 데 초점을 맞추는데, 이는 결론의 범위를 잘 한정하면서도 여전히 실용적으로 가치가 있다.
- DFM은 독립형 추론 전용 가속기라기보다는 더 나은 점진적 생성을 위한 학습 시점 프레임워크로 보는 것이 가장 좋으며, 그 단순성은 더 빠른 샘플링과 배치에 관한 향후 시스템 연구와 상호 보완적이게 만든다.
이 결과를 읽는 방법
이 논문은 점진적 시각 생성에 대한 강력하고 우아한 기여로 읽는 것이 가장 좋다. DFM은 단일 Flow Matching 모델로 거친-에서-세밀한 합성의 이점을 포착하고, 벤치마크 전반에 걸쳐 이미지 및 비디오 품질을 향상시키며, 대형 생성 시스템의 더 나은 미세조정을 위한 실용적인 경로를 제공한다.