Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Resumo do comunicado de imprensa
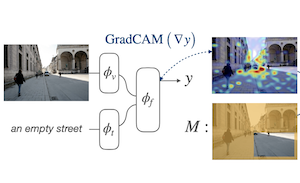
Pesquisadores da Rice University e da Adobe Research desenvolveram uma nova técnica de treinamento que melhora como os modelos de IA de visão e linguagem localizam objetos e regiões em imagens quando recebem uma descrição textual. O problema que eles enfrentaram é que, embora grandes modelos treinados em pares imagem-texto em escala de internet consigam associar de forma vaga palavras a regiões de imagem, eles não são explicitamente ensinados a localizar coisas com precisão. A abordagem da equipe, chamada Attention Mask Consistency (AMC), funciona observando os "mapas de calor de explicação" baseados em gradiente que um modelo naturalmente produz ao decidir se uma imagem e um texto combinam, e então penalizando o modelo durante o treinamento sempre que esses mapas de calor destacam as partes erradas da imagem — ou seja, regiões fora das áreas anotadas por humanos. A penalidade assume a forma de uma perda de margem que empurra o modelo a concentrar a energia do mapa de calor dentro das regiões anotadas, em vez de fora delas. Crucialmente, o método não requer um detector de objetos como intermediário, que é como a maioria das abordagens concorrentes funciona, e pode ser sobreposto a um modelo existente — neste caso o ALBEF — sem retreinar do zero. No benchmark de ancoragem visual Flickr30k, um modelo treinado com AMC alcançou 86,49% de acurácia, uma melhoria de mais de cinco pontos percentuais em relação ao melhor resultado publicado anteriormente sob supervisão comparável, e também estabeleceu novas marcas no conjunto de dados de expressões referenciais RefCOCO+. O trabalho é importante porque oferece um caminho relativamente leve para um melhor raciocínio espacial em modelos de visão e linguagem sem exigir a cara infraestrutura de um detector de objetos treinado.
resumo
Propomos uma perda baseada em margem para ajustar modelos conjuntos de visão e linguagem de modo que suas explicações baseadas em gradiente sejam consistentes com anotações em nível de região fornecidas por humanos para conjuntos de dados de ancoragem relativamente menores. Referimo-nos a esse objetivo como Attention Mask Consistency (AMC) e demonstramos que ele produz resultados de ancoragem visual superiores aos métodos anteriores que dependem do uso de modelos de visão e linguagem para pontuar as saídas de detectores de objetos. Particularmente, um modelo treinado com AMC sobre objetivos padrão de modelagem de visão e linguagem obtém uma acurácia de estado da arte de 86,49% no benchmark de ancoragem visual Flickr30k, uma melhoria absoluta de 5,38% em comparação com o melhor modelo anterior treinado sob o mesmo nível de supervisão. Nossa abordagem também tem desempenho excepcionalmente bom em benchmarks estabelecidos de compreensão de expressões referenciais, nos quais obtém 80,34% de acurácia no teste fácil do RefCOCO+ e 64,55% na divisão difícil. O AMC é eficaz, fácil de implementar e geral, pois pode ser adotado por qualquer modelo de visão e linguagem e pode usar qualquer tipo de anotação de região.
detalhes
citação
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}