Going Beyond Nouns With Vision & Language Models Using Synthetic Data
News Release Summary
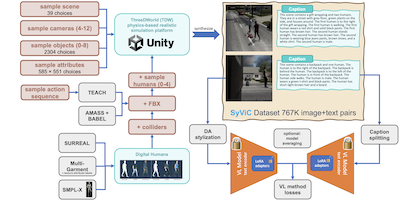
Researchers from MIT, IBM, Rice University, and several other institutions have identified and taken a practical step toward fixing a persistent blind spot in popular AI vision-language models like CLIP: these systems are surprisingly bad at understanding anything beyond the objects in an image, struggling to grasp attributes, spatial relationships, actions, and word order in ways that humans find trivial. To address this, the team built a million-image synthetic dataset called SyViC — Synthetic Visual Concepts — by running physics-based 3D simulations in the ThreeDWorld engine, populating scenes with randomized objects, materials, and animated human avatars dressed in diverse clothing, then automatically generating detailed text captions from the scene metadata. The key insight is that synthetic environments allow researchers to cheaply create image-text pairs that deliberately highlight the exact non-noun concepts the models miss, something that is prohibitively difficult and expensive to do with real-world photographs. When they fine-tuned CLIP and CyCLIP on SyViC using a combination of low-rank parameter adaptation (LoRA), style-transfer-based domain adaptation, and a caption-splitting technique to handle longer descriptive text, the models improved by up to 9.9% on the ARO compositional reasoning benchmark and 4.3% on the VL-Checklist evaluation, while sacrificing less than one percent of their zero-shot classification accuracy across 21 tasks. The work matters because it demonstrates that targeted synthetic data, without any real images, can meaningfully patch a well-documented structural weakness in contrastive vision-language training, and the team has released both the dataset and code publicly.
abstract
Large-scale pre-trained Vision & Language (VL) models have shown remarkable performance in many applications, enabling replacing a fixed set of supported classes with zero-shot open vocabulary reasoning over (almost arbitrary) natural language prompts. However, recent works have uncovered a fundamental weakness of these models. For example, their difficulty to understand Visual Language Concepts (VLC) that go 'beyond nouns' such as the meaning of non-object words (e.g., attributes, actions, relations, states, etc.), or difficulty in performing compositional reasoning such as understanding the significance of the order of the words in a sentence. In this work, we investigate to which extent purely synthetic data could be leveraged to teach these models to overcome such shortcomings without compromising their zero-shot capabilities. We contribute Synthetic Visual Concepts (SyViC) - a million-scale synthetic dataset and data generation codebase allowing to generate additional suitable data to improve VLC understanding and compositional reasoning of VL models. Additionally, we propose a general VL finetuning strategy for effectively leveraging SyViC towards achieving these improvements. Our extensive experiments and ablations on VL-Checklist, Winoground, and ARO benchmarks demonstrate that it is possible to adapt strong pre-trained VL models with synthetic data significantly enhancing their VLC understanding (e.g. by 9.9% on ARO and 4.3% on VL-Checklist) with under 1% drop in their zero-shot accuracy.
details
citation
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}