Taming Data and Transformers for Audio Generation
News Release Summary
Researchers from Rice University and Snap Inc. have tackled a persistent bottleneck in AI-generated ambient sound — the shortage of large, well-labeled training data and models that fail to improve as they grow larger. To address the data problem, the team developed an automated pipeline that mines ambient audio clips from existing YouTube-based video datasets by identifying segments where no speech or music transcription is present, sidestepping the need to download and run expensive classifiers on raw video. The result is AutoReCap-XL, a dataset of 47 million ambient audio clips with text descriptions, roughly 75 times larger than what was previously available. To generate those descriptions, they built AutoCap, an audio captioning model that incorporates a Q-Former module alongside visual metadata such as video titles and frame-level captions, reaching a CIDEr score of 83.2 on the standard AudioCaps benchmark — a 3.2% improvement over prior methods. On the generation side, they introduced GenAu, a transformer-based diffusion model scaled up to 1.25 billion parameters that borrows a "FIT" architecture originally designed for video, using local and global attention layers to focus compute on informative audio segments rather than spreading it uniformly over silent or redundant portions. Compared to comparable baselines, GenAu improved Inception Score by 11.1%, Fréchet Audio Distance by 4.7%, and CLAP text-alignment score by 13.5%, and — unlike previous large audio models — continued to improve consistently as both model size and dataset size increased, suggesting the field may finally have a recipe for scaling ambient sound generation the way image and video generation has already been scaled.
abstract
The scalability of ambient sound generators is hindered by data scarcity, insufficient caption quality, and limited scalability in model architecture. This work addresses these challenges by advancing both data and model scaling. First, we propose an efficient and scalable dataset collection pipeline tailored for ambient audio generation, resulting in AutoReCap-XL, the largest ambient audio-text dataset with over 47 million clips. To provide high-quality textual annotations, we propose AutoCap, a high-quality automatic audio captioning model. By adopting a Q-Former module and leveraging audio metadata, AutoCap substantially enhances caption quality, reaching a CIDEr score of $83.2$, a $3.2\%$ improvement over previous captioning models. Finally, we propose GenAu, a scalable transformer-based audio generation architecture that we scale up to 1.25B parameters. We demonstrate its benefits from data scaling with synthetic captions as well as model size scaling. When compared to baseline audio generators trained at similar size and data scale, GenAu obtains significant improvements of $4.7\%$ in FAD score, $11.1\%$ in IS, and $13.5\%$ in CLAP score. Our code, model checkpoints, and dataset are publicly available.
details
citation
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What problem does this paper solve? It addresses the main barriers to scalable ambient sound generation: scarce audio-text data, weak caption quality, and generator architectures that have not benefited reliably from scaling.
- What is AutoReCap-XL? AutoReCap-XL is a very large ambient audio-text dataset with over 47 million clips collected by filtering online video segments for non-speech, non-music audio and recaptioning them automatically.
- What is AutoCap? AutoCap is an automatic audio captioning model that combines audio features, a Q-Former, BART decoding, and metadata such as video titles and visual captions to produce higher-quality audio descriptions.
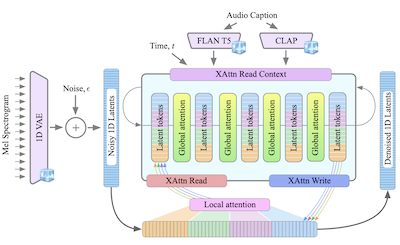
- What is GenAu? GenAu is a transformer-based latent diffusion model for text-to-audio generation that adapts a FIT-style architecture with local and global attention to the temporal structure of audio.
- Why is scaling important in this work? The paper shows that GenAu improves with both more synthetic captioned data and larger model size, which is important because earlier ambient audio generators often showed weak or inconsistent scaling behavior.
Main contributions
- The paper introduces AutoReCap-XL, described as the largest ambient audio-text dataset in the work, with 47 million clips and roughly 123.5k hours of audio drawn from large-scale video sources.
- It proposes AutoCap, a strong audio captioner that uses a Q-Former and metadata to improve caption quality, reaching a CIDEr score of 83.2 on AudioCaps.
- It presents GenAu, a scalable transformer-based text-to-audio diffusion architecture that uses a 1D VAE latent space and FIT-inspired local/global attention for efficient audio generation.
- The experiments show clear improvements over comparable text-to-audio baselines, including gains in FAD, Inception Score, and CLAP alignment.
- The paper provides an unusually complete scaling recipe for ambient audio generation by improving the dataset, captioning pipeline, and model architecture together rather than treating them as separate problems.
Limitations and cautions
- AutoCap is fine-tuned on AudioCaps, whose vocabulary is limited, so very detailed or unusual prompts may still be challenging; the paper frames this as a direct path for future captioner and dataset improvements.
- AutoReCap-XL is validated primarily through audio generation experiments, which is a strong first use case while leaving audio retrieval, audio understanding, and audio-video tasks as promising extensions.
- The data collection pipeline relies on transcripts, metadata, and filtering heuristics, but this is also what makes it efficient enough to scale far beyond manually captioned ambient audio datasets.
- GenAu targets ambient sound rather than speech or music generation, giving the paper a focused contribution while leaving related audio domains as natural opportunities for adaptation.
- Large-scale training and a 1.25B-parameter model require meaningful compute, but the results make a strong case that this investment yields better scaling behavior for ambient audio generation.
How to read this result
This paper is best read as a major systems-level advance for ambient audio generation: by pairing a massive recaptioned dataset, a stronger captioning model, and a scalable transformer diffusion generator, it gives the field a practical recipe for improving text-to-audio quality through both data and model scaling.