Instance-level Image Retrieval using Reranking Transformers
News Release Summary
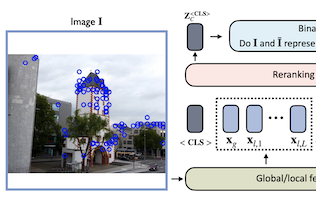
Researchers from the University of Virginia, eBay, and Rice University have developed a lightweight neural network model called the Reranking Transformer, or RRT, that improves the accuracy of image search systems that try to identify specific objects or landmarks rather than broad categories. The problem the team tackled is a two-step process common in image retrieval: a first pass uses a compact global image descriptor to pull up a shortlist of candidate matches, and a second pass refines that list using more detailed local features — a step traditionally handled by geometric verification, a computationally expensive technique that tries to estimate how one image can be geometrically warped to match another. The researchers replaced that second step with a small transformer-based model, borrowing the attention-based architecture that has driven recent advances in natural language processing, and trained it to directly predict whether two images show the same object or scene. With only about 2.2 million parameters — roughly 9 percent of the size of a standard ResNet50 backbone — and requiring only half as many local feature descriptors as geometric verification, RRT nonetheless outperformed geometric verification and other competing approaches on standard benchmarks including the Revisited Oxford and Paris datasets and Google Landmarks v2. A key practical advantage is that reranking an entire shortlist of 100 candidate images takes only a single forward pass through the network. The researchers also showed that, unlike geometric verification, RRT can be trained jointly with the underlying feature extractor, allowing the two components to be optimized together and yielding further accuracy gains, a capability they demonstrated on the Stanford Online Products dataset.
abstract
Instance-level image retrieval is the task of searching in a large database for images that match an object in a query image. To address this task, systems usually rely on a retrieval step that uses global image descriptors, and a subsequent step that performs domain-specific refinements or reranking by leveraging operations such as geometric verification based on local features. In this work, we propose Reranking Transformers (RRTs) as a general model to incorporate both local and global features to rerank the matching images in a supervised fashion and thus replace the relatively expensive process of geometric verification. RRTs are lightweight and can be easily parallelized so that reranking a set of top matching results can be performed in a single forward-pass. We perform extensive experiments on the Revisited Oxford and Paris datasets, and the Google Landmarks v2 dataset, showing that RRTs outperform previous reranking approaches while using much fewer local descriptors. Moreover, we demonstrate that, unlike existing approaches, RRTs can be optimized jointly with the feature extractor, which can lead to feature representations tailored to downstream tasks and further accuracy improvements. The code and trained models are publicly available at https://github.com/uvavision/RerankingTransformer.
details
citation
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}