MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
News Release Summary
Researchers at Meta and Rice University have developed MetaEmbed, a new approach to multimodal search that allows systems to adjust their accuracy and speed on demand. Current multimodal retrieval systems, which search across text and images, face a trade-off between precision and computational efficiency—they either compress everything into a single vector that loses detail, or use hundreds of vectors that become too slow for practical use. MetaEmbed introduces learnable "Meta Tokens" that create a small set of contextualized embeddings organized from coarse to fine-grained information. This design enables users to select how many vectors to use during search, balancing quality against speed requirements. Testing on standard benchmarks shows the system achieves state-of-the-art performance while scaling
abstract
Universal multimodal embedding models have achieved great success in capturing semantic relevance between queries and candidates. However, current methods either condense queries and candidates into a single vector, potentially limiting the expressiveness for fine-grained information, or produce too many vectors that are prohibitive for multi-vector retrieval. In this work, we introduce MetaEmbed, a new framework for multimodal retrieval that rethinks how multimodal embeddings are constructed and interacted with at scale. During training, a fixed number of learnable Meta Tokens are appended to the input sequence. At test-time, their last-layer contextualized representations serve as compact yet expressive multi-vector embeddings. Through the proposed Matryoshka Multi-Vector Retrieval training, MetaEmbed learns to organize information by granularity across multiple vectors. As a result, we enable test-time scaling in multimodal retrieval where users can balance retrieval quality against efficiency demands by selecting the number of tokens used for indexing and retrieval interactions. Extensive evaluations on the Massive Multimodal Embedding Benchmark (MMEB) and the Visual Document Retrieval Benchmark (ViDoRe) confirm that MetaEmbed achieves state-of-the-art retrieval performance while scaling robustly to models with 32B parameters. Code is available at https://github.com/facebookresearch/MetaEmbed.
details
citation
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
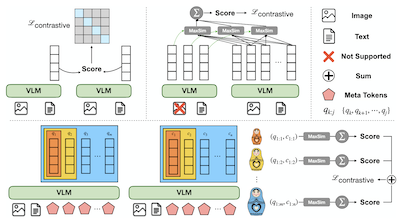
- What is MetaEmbed and what problem does it address? MetaEmbed is a multimodal retrieval framework that uses compact learnable Meta Tokens to provide more expressive retrieval than single-vector embeddings without the heavy cost of hundreds of patch-level vectors.
- How does MetaEmbed enable test-time scaling? It trains nested groups of Meta Embeddings through Matryoshka Multi-Vector Retrieval, so users can choose smaller or larger retrieval budgets at indexing and scoring time without retraining.
- Why are Meta Tokens useful for multimodal retrieval? Their final-layer contextualized states act as a small set of multi-vector embeddings that preserve fine-grained query-candidate interactions while keeping index size and scoring cost controllable.
- How well does MetaEmbed perform on MMEB? The paper reports that Qwen2.5-VL initialized MetaEmbed reaches 76.6 overall Precision@1 with a 7B model and 78.7 with a 32B model, outperforming the listed baselines.
- Does MetaEmbed work for visual document retrieval? Yes, the paper evaluates on ViDoRe and shows that retrieval quality improves as more Meta Embeddings are used, while MMR preserves strong performance at low retrieval budgets.
Main contributions
- The paper introduces Meta Tokens as compact contextualized multi-vector embeddings for multimodal retrieval across text, image, and mixed-modality queries and candidates.
- Matryoshka Multi-Vector Retrieval trains coarse-to-fine nested embedding groups, enabling a single model and index design to support multiple quality-latency operating points.
- MetaEmbed achieves state-of-the-art results on MMEB and strong results on ViDoRe while scaling to 32B vision-language model backbones.
- The ablations show that multi-vector retrieval benefits grow with model scale and that MMR is important for preserving low-budget retrieval quality.
- The efficiency analysis shows that scoring latency remains small for moderate budgets and that index memory can be managed by choosing balanced retrieval settings.
Limitations and cautions
- Higher retrieval budgets increase index memory, but the nested design makes this a user-controllable tradeoff rather than a fixed deployment cost.
- The largest budget can increase scoring FLOPs substantially, yet the measured latency stays practical for many settings and the paper shows useful accuracy at much smaller budgets.
- MetaEmbed still requires fine-tuning strong VLM backbones, so future work could explore lighter training recipes; the LoRA setup and multi-architecture experiments already make the approach broadly accessible.
- The evaluation focuses on standard multimodal and visual-document retrieval benchmarks, leaving very large production indexes and specialized enterprise domains as natural deployment studies.
- The method targets retrieval rather than generation or question answering directly, but better flexible retrieval is a valuable building block for retrieval-augmented multimodal systems.
How to read this result
This paper is best read as a strong contribution to scalable multimodal retrieval: MetaEmbed preserves fine-grained late interaction, adds a practical test-time budget knob, and shows that larger VLMs can become more effective retrieval models when given compact multi-vector interfaces.