Commonly Uncommon: Semantic Sparsity in Situation Recognition
News Release Summary
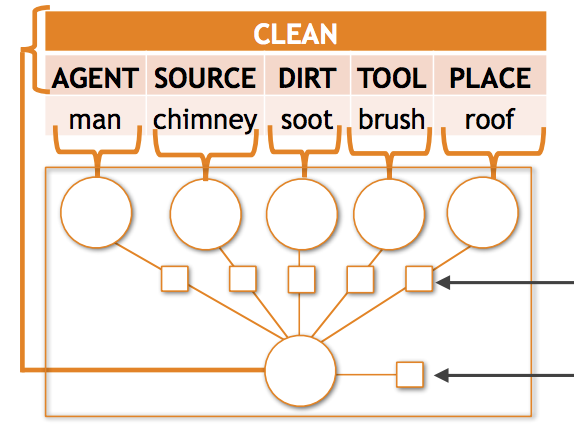
Researchers at the University of Washington and the Allen Institute for Artificial Intelligence have tackled a stubborn problem in computer vision: when AI systems try to describe what is happening in a photo in structured detail — identifying not just an activity like "carrying" but also who is carrying, what they are carrying, and where — they tend to fall apart whenever the scene involves an unusual combination of objects and roles. The team found that in the imSitu benchmark dataset, roughly 35 percent of required predictions involve object-role pairings seen fewer than ten times during training, and existing models lose significant accuracy in exactly those cases. To address this, the researchers developed two complementary techniques. First, they designed a new mathematical model called a compositional tensor potential, embedded within a Conditional Random Field framework, that learns shared representations of nouns across different roles — so that knowledge about what a "baby" looks like, for instance, can inform predictions regardless of whether the baby appears as the thing being carried or the person doing the carrying. Second, they built a semantic data augmentation pipeline that converts annotated training situations into short text phrases, uses those phrases to retrieve roughly five million images from Google image search, and incorporates the noisy results through marginal likelihood training and iterative self-training. Combining both approaches improved top-5 verb accuracy by about 6 percent and noun-role accuracy by nearly 10 percent over the prior state of the art, with even larger relative gains on the rare cases the work specifically targets. The findings matter because semantic sparsity — too many possible output combinations, too few examples of most of them — is a widespread obstacle in structured visual understanding tasks, and this work offers a concrete, scalable strategy for making AI systems more reliable when encountering the uncommon situations that are, in practice, quite common in the real world.
abstract
Semantic sparsity is a common challenge in structured visual classification problems; when the output space is complex, the vast majority of the possible predictions are rarely, if ever, seen in the training set. This paper studies semantic sparsity in situation recognition, the task of producing structured summaries of what is happening in images, including activities, objects and the roles objects play within the activity. For this problem, we find empirically that most object-role combinations are rare, and current state-of-the-art models significantly underperform in this sparse data regime. We avoid many such errors by (1) introducing a novel tensor composition function that learns to share examples across role-noun combinations and (2) semantically augmenting our training data with automatically gathered examples of rarely observed outputs using web data. When integrated within a complete CRF-based structured prediction model, the tensor-based approach outperforms existing state of the art by a relative improvement of 2.11% and 4.40% on top-5 verb and noun-role accuracy, respectively. Adding 5 million images with our semantic augmentation techniques gives further relative improvements of 6.23% and 9.57% on top-5 verb and noun-role accuracy.
citation
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}