Obj2Text: Generating Visually Descriptive Language from Object Layouts
News Release Summary
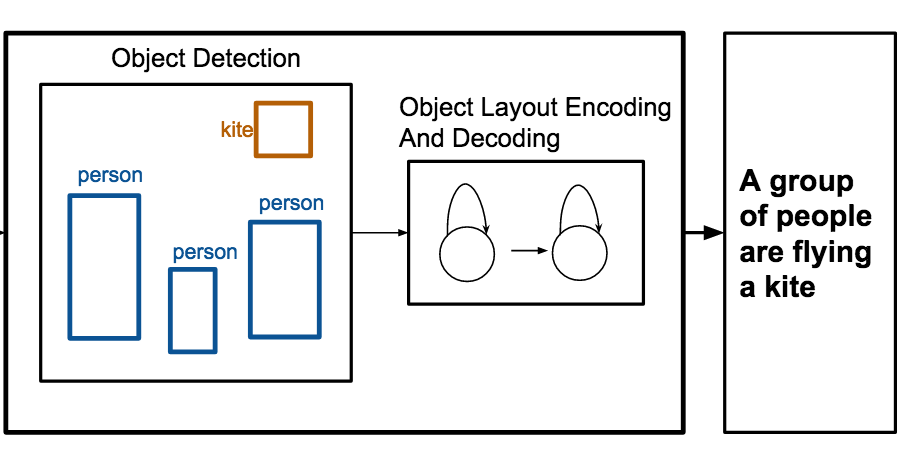
Researchers at the University of Virginia have built a system that can automatically write captions describing a scene using nothing more than a list of objects and their positions in an image, bypassing the need for raw pixel data. The system, called OBJ2TEXT, works by feeding object labels and their bounding box coordinates into one neural network that encodes the layout as a sequence, and then passing that encoded representation to a second neural network that generates a sentence word by word. Testing on the standard MS-COCO image dataset, the team found that object location and object count both meaningfully improved caption quality — removing either one caused measurable drops in performance — demonstrating that even a sequential encoding of spatial information carries real descriptive value. Perhaps more practically, when the researchers combined OBJ2TEXT with an object detector called YOLO and a conventional image-based captioning model, the hybrid system outperformed the image-only captioning baseline, pushing its CIDEr score from 0.863 to 0.950 on the MS-COCO benchmark; human evaluators also preferred the combined system's captions roughly 65 percent of the time when they all agreed. The work matters because it shows that structured, symbolic information about a scene — the kind produced by object detectors or used in graphic design and storyboarding — can complement or even partially substitute for pixel-level visual features in language generation, offering a cleaner way to study what image captioning models actually need to know about a scene.
abstract
Generating captions for images is a task that has recently received considerable attention. In this work we focus on caption generation for abstract scenes, or object layouts where the only information provided is a set of objects and their locations. We propose OBJ2TEXT, a sequence-to-sequence model that encodes a set of objects and their locations as an input sequence using an LSTM network, and decodes this representation using an LSTM language model. We show that our model, despite encoding object layouts as a sequence, can represent spatial relationships between objects, and generate descriptions that are globally coherent and semantically relevant. We test our approach in a task of object-layout captioning by using only object annotations as inputs. We additionally show that our model, combined with a state-of-the-art object detector, improves an image captioning model from 0.863 to 0.950 (CIDEr score) in the test benchmark of the standard MS-COCO Captioning task.
details
citation
@inproceedings{yin2017obj,
title = {Obj2Text: Generating Visually Descriptive Language from Object Layouts},
author = {Yin, Xuwang and Ordonez, Vicente},
year = {2017},
booktitle = {Empirical Methods in Natural Language Processing. EMNLP 2017},
url = {https://arxiv.org/abs/1707.07102},
}