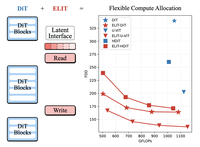
One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Краткое изложение пресс-релиза
Исследователи из Rice University и Snap Inc. разработали технику под названием ELIT (сокращение от Elastic Latent Interface Transformer), которая даёт моделям генерации изображений и видео возможность на лету находить компромисс между скоростью вычислений и качеством результата — без переобучения модели под каждую желаемую рабочую точку. Основная проблема, которую они решали, состоит в том, что стандартные модели diffusion transformer тратят одинаковый объём вычислений на каждый участок изображения независимо от того, содержит ли этот участок тонкие детали или пустое небо, и при этом они привязаны к фиксированной вычислительной стоимости, зависящей от разрешения изображения. Чтобы это исправить, команда вставила небольшой набор обучаемых «латентных токенов» между ранними и поздними стадиями обработки модели, соединённых двумя лёгкими cross-attention слоями, которые они называют Read и Write. Во время обучения модель случайным образом отбрасывает часть этих латентных токенов, что вынуждает её упаковывать наиболее важную информацию в токены, которые она сохраняет чаще всего, формируя естественным образом упорядоченное представление. На этапе инференса пользователь может просто выбрать, сколько латентных токенов использовать, напрямую увеличивая или уменьшая объём вычислений. Протестированный на нескольких популярных архитектурах, включая DiT, U-ViT, HDiT и 20-миллиардную модель Qwen-Image, ELIT стабильно улучшал метрики качества изображений — снижая показатели FID вплоть до 53% на 512-пиксельных бенчмарках ImageNet — и при этом позволял пользователям сокращать вычисления примерно на 35–65% лишь с умеренной потерей качества. Подход также открывает более дешёвую форму classifier-free guidance, используя версию той же модели с малым числом токенов как встроенную «слабую» референсную модель, снижая затраты на guidance примерно на треть.
аннотация
Diffusion transformers (DiTs) достигают высокого качества генерации, но привязывают объём вычислений (FLOPs) к разрешению изображения, ограничивая принципиальные компромиссы между задержкой и качеством, а также распределяют вычисления равномерно по входным пространственным токенам, тратя ресурсы на неважные области. Мы представляем Elastic Latent Interface Transformer (ELIT) — подключаемый, совместимый с DiT механизм, который отделяет размер входного изображения от объёма вычислений. Наш подход вставляет латентный интерфейс — обучаемую последовательность токенов переменной длины, над которой могут работать стандартные блоки трансформера. Лёгкие cross-attention слои Read и Write перемещают информацию между пространственными токенами и латентами и приоритизируют важные входные области. Обучаясь со случайным отбрасыванием хвостовых латентов, ELIT учится формировать упорядоченные по важности представления, где более ранние латенты захватывают глобальную структуру, а более поздние содержат информацию для уточнения деталей. На этапе инференса число латентов можно динамически подстраивать под ограничения по вычислениям. ELIT намеренно минималистичен: он добавляет два cross-attention слоя, оставляя без изменений цель rectified flow и стек DiT. На разных наборах данных и архитектурах (DiT, U-ViT, HDiT, MM-DiT) ELIT обеспечивает стабильный прирост. На ImageNet-1K 512px ELIT даёт средний прирост $35.3\%$ и $39.6\%$ по метрикам FID и FDD. Страница проекта: https://snap-research.github.io/elit/
подробности
цитирование
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое ELIT и какую проблему он решает? ELIT — это подключаемый механизм латентного интерфейса для diffusion transformers, который отделяет вычисления от разрешения изображения и позволяет одной генеративной модели работать в нескольких режимах качества и задержки.
- Как ELIT изменяет diffusion transformer? Он вставляет набор латентных токенов переменной длины между короткой пространственной «головой» и «хвостом», используя лёгкие cross-attention слои Read и Write для перемещения информации между токенами изображения и латентным интерфейсом.
- Как ELIT обеспечивает гибкие бюджеты инференса? Во время обучения хвостовые латентные токены случайно отбрасываются, поэтому более ранние токены усваивают наиболее важную информацию, а на этапе инференса пользователи выбирают, сколько латентных токенов оставить, чтобы контролировать FLOPs.
- Какие эмпирические улучшения сообщает ELIT? На ImageNet-1K 512px ELIT существенно улучшает FID и FDD на бэкбонах DiT, U-ViT и HDiT, включая улучшение FID вплоть до 53 процентов для конфигурации DiT, представленной в статье.
- Масштабируется ли ELIT на крупные генеративные модели? Да, в статье ELIT применяется к Qwen-Image — модели MM-DiT на 20B параметров — и демонстрируется плавный компромисс между вычислениями и качеством с ускорением примерно до 2.7x при сохранении высоких показателей DPG-Bench.
Основные вклады
- В статье представлен минимальный латентный интерфейс Read/Write, который оставляет неизменными цель rectified-flow и основной стек DiT, что делает ELIT простым для встраивания в существующие семейства diffusion transformer.
- ELIT демонстрирует адаптивные вычисления, используя слой Read для перетягивания информативных пространственных областей в латентный интерфейс вместо равномерной траты вычислений на простые или дополненные паддингом области.
- Стратегия обучения с несколькими бюджетами создаёт упорядоченную по важности латентную последовательность, позволяя одному набору весов поддерживать множество бюджетов инференса без переобучения.
- Эксперименты показывают стабильное улучшение генерации изображений на DiT, U-ViT и HDiT, благоприятные результаты генерации видео на Kinetics-700 и совместимость с методами ускорения без обучения, такими как TeaCache.
- ELIT обеспечивает дешёвые guidance и autoguidance, используя версии той же модели с меньшим бюджетом как слабые референсы, снижая стоимость guidance при одновременном улучшении качества сэмплов.
Ограничения и предостережения
- ELIT добавляет слои Read и Write, а также планирование латентных токенов, поэтому это небольшое архитектурное изменение, а не чисто безобучательный метод ускорения; подключаемый дизайн и широкие результаты по бэкбонам хорошо оправдывают эту добавленную сложность.
- Эксперимент с Qwen-Image дообучает крупную существующую модель на доступных реальных и синтетических данных, а не воспроизводит полный проприетарный обучающий конвейер исходной модели, но он всё же даёт ценное свидетельство того, что ELIT масштабируется на системы MM-DiT с 20B параметрами.
- Конфигурации Qwen-Image с самым низким бюджетом жертвуют частью качества на бенчмарках ради скорости, что ожидаемо для эластичной модели и полезно, поскольку пользователи могут выбрать бюджет, отвечающий их требованиям к задержке и качеству.
- Большинство детальных абляций проведены на условных по классам конфигурациях ImageNet и Kinetics, оставляя детали развёртывания для генерации изображений из текста и пользовательские предпочтения по качеству естественными направлениями будущей оценки.
- Метод улучшает распределение вычислений внутри генераторов типа DiT, а не заменяет все прочие техники эффективности, и совместимость с TeaCache и стратегиями guidance говорит о том, что его можно продуктивно сочетать с дополняющими ускорителями.
Как интерпретировать этот результат
Эту статью лучше всего воспринимать как сильный системно-модельный вклад для diffusion transformers: ELIT даёт одной модели практический контроль над бюджетами вычислений, улучшает качество генерации на нескольких бэкбонах и масштабирует идею на крупные современные генераторы изображений, сохраняя при этом компактность изменений в ядре архитектуры.