Where and Who? Automatic Semantic-Aware Person Composition
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu tại University of Virginia đã xây dựng một hệ thống có thể tự động chèn một hình người trông chân thực vào một bức ảnh mà không cần bất kỳ sự hướng dẫn nào từ con người về việc đặt họ ở đâu hoặc dùng ai. Hầu hết các công cụ ghép ảnh hiện có xử lý phần kỹ thuật của việc hòa trộn các cạnh và khớp màu sắc, nhưng vẫn để người dùng tự chọn một chủ thể tiền cảnh, chọn nơi đặt nó, và quyết định nó nên lớn cỡ nào. Hệ thống mới giải quyết những phán đoán đó một cách tính toán bằng cách huấn luyện một mạng nơ-ron tích chập phân nhánh trên hàng chục nghìn ảnh được chú thích từ bộ dữ liệu MS-COCO, dạy nó dự đoán các vị trí và kích thước hợp lý cho một người chỉ với khung cảnh nền. Một khi một bounding box được dự đoán, hệ thống tìm kiếm trong một bể gồm khoảng 4.100 hình người được cắt ra và phân đoạn thủ công, sử dụng các đặc trưng sâu từ một mô hình ResNet50 đã tiền huấn luyện để khớp cả loại khung cảnh tổng thể lẫn vùng lân cận cục bộ ngay sát trước khi hòa trộn hình được chọn vào bằng alpha matting. Trong một nghiên cứu người dùng huy động đám đông trên Amazon Mechanical Turk, các giám khảo là con người đánh giá các ảnh ghép của hệ thống là thật khoảng 44 phần trăm thời gian, so với khoảng 18 đến 28 phần trăm cho ba phương pháp baseline, mặc dù các ảnh thật vẫn đạt khoảng 90 phần trăm. Khoảng cách thu hẹp đáng kể khi kết cấu và ánh sáng bị loại bỏ, cho thấy rằng sự không khớp về màu sắc và ánh sáng — chứ không phải vị trí đặt hay việc chọn hình — là trở ngại chính còn lại. Các nhà nghiên cứu cho biết công trình này đại diện cho một bước đầu tiên hướng tới các công cụ có thể hỗ trợ các nhà thiết kế đồ họa, nhà làm phim và họa sĩ vẽ phân cảnh, những người hiện đang dành nhiều thời gian để lắp ráp thủ công những khung cảnh như vậy.
tóm tắt
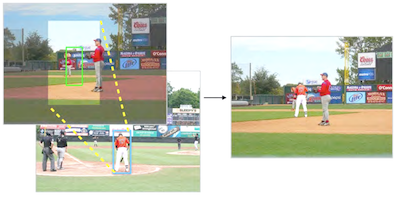
Ghép ảnh (image compositing) là một phương pháp được dùng để tạo ra hình ảnh trông chân thực nhưng là giả mạo bằng cách chèn nội dung từ một ảnh này vào một ảnh khác. Các công trình trước đây về ghép ảnh đã tập trung vào việc cải thiện tính tương thích về diện mạo của một phân đoạn tiền cảnh do người dùng chọn và một ảnh nền (tức là tính nhất quán về màu sắc và ánh sáng). Trong công trình này, thay vào đó chúng tôi phát triển một mô hình ghép ảnh hoàn toàn tự động, ngoài ra còn học cách chọn và biến đổi các phân đoạn tiền cảnh tương thích từ một bộ sưu tập lớn chỉ với một ảnh nền đầu vào. Để đơn giản hóa nhiệm vụ, chúng tôi giới hạn bài toán bằng cách tập trung vào việc ghép thực thể người, bởi vì các phân đoạn người thể hiện mối tương quan mạnh với nền của chúng và bởi vì có sẵn dữ liệu được chú thích quy mô lớn. Chúng tôi phát triển một mạng nơ-ron tích chập (CNN) phân nhánh mới mẻ dự đoán đồng thời các vị trí ứng viên của người khi cho một ảnh nền. Sau đó chúng tôi sử dụng các biểu diễn đặc trưng sâu đã tiền huấn luyện để truy hồi các thực thể người từ một cơ sở dữ liệu phân đoạn lớn. Các kết quả thực nghiệm cho thấy mô hình của chúng tôi có thể tạo ra các ảnh ghép trông thuyết phục về mặt thị giác. Chúng tôi cũng phát triển một giao diện người dùng để minh họa ứng dụng tiềm năng của phương pháp.
chi tiết
trích dẫn
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}