Grounding Language Models for Visual Entity Recognition
Tóm tắt thông cáo báo chí
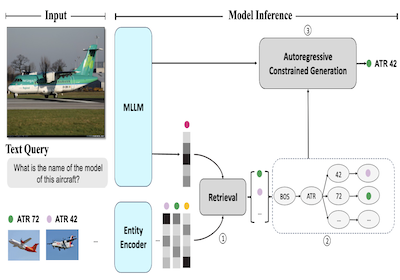
Các nhà nghiên cứu tại Rice University và Microsoft đã phát triển một hệ thống tên là AutoVER, cải thiện đáng kể khả năng của máy tính trong việc nhận dạng các thực thể cụ thể trong thế giới thực trong ảnh — chẳng hạn phân biệt một mẫu máy bay cụ thể này với một mẫu khác gần như giống hệt — bằng cách neo các phỏng đoán của một mô hình ngôn ngữ AI vào một cơ sở tri thức cụ thể thay vì để nó sinh ra bất kỳ câu trả lời nào có vẻ hợp lý. Vấn đề cốt lõi là các hệ thống AI đa phương thức hiện có, vốn xử lý cả ảnh và văn bản, thường ảo giác hoặc đưa ra câu trả lời ở mức độ cụ thể không đúng khi được hỏi các câu hỏi nhận dạng chi tiết, chẳng hạn xác định liệu một chiếc máy bay trong ảnh là ATR 42 hay British Aerospace 146. AutoVER giải quyết vấn đề này bằng cách kết hợp hai kỹ thuật: nó huấn luyện mô hình truy hồi các thực thể ứng viên tương tự về mặt thị giác và ngữ nghĩa từ một cơ sở dữ liệu hơn sáu triệu mục Wikipedia bằng cách dùng cách tiếp cận Contrastive Learning, và sau đó trong quá trình sinh câu trả lời, nó giới hạn đầu ra của mô hình chỉ trong các ứng viên đã được truy hồi bằng cách xây dựng một cây tiền tố (prefix tree) chặn bất kỳ chuỗi token nào dẫn đến câu trả lời không hợp lệ. Hệ thống được thử nghiệm trên benchmark Oven-Wiki, một bộ dữ liệu quy mô lớn được thiết kế riêng cho loại thách thức nhận dạng thực thể thị giác này, nơi nó đẩy độ chính xác trên các thực thể mà mô hình đã thấy trong quá trình huấn luyện từ khoảng 32,7 phần trăm lên 61,5 phần trăm, đồng thời vượt trội hơn các mô hình lớn hơn nhiều như PaLI-17B của Google trên các ví dụ liên quan đến các thực thể chưa thấy và các câu hỏi đòi hỏi suy luận thị giác. Công trình này quan trọng vì việc nhận dạng thực thể đáng tin cậy từ ảnh có các ứng dụng thực tế trong nhiều lĩnh vực, từ công cụ tìm kiếm đến công cụ hỗ trợ tiếp cận, và cách tiếp cận này chứng minh rằng việc kết nối chặt chẽ truy hồi với sinh có ràng buộc là một con đường đáng tin cậy hơn so với việc chỉ đơn thuần mở rộng quy mô mô hình và hy vọng nó đưa ra được các câu trả lời đủ cụ thể.
tóm tắt
Chúng tôi giới thiệu AutoVER, một mô hình Tự hồi quy cho Nhận dạng Thực thể Thị giác (Visual Entity Recognition). Mô hình của chúng tôi mở rộng một Mô hình Ngôn ngữ Lớn Đa phương thức tự hồi quy bằng cách sử dụng sinh có ràng buộc được tăng cường bằng truy hồi (retrieval augmented constrained generation). Nó giảm thiểu hiệu năng thấp trên các thực thể ngoài miền trong khi vượt trội ở các truy vấn đòi hỏi suy luận đặt trong bối cảnh thị giác. Phương pháp của chúng tôi học cách phân biệt các thực thể tương tự trong một không gian nhãn rộng lớn bằng cách huấn luyện tương phản trên các cặp negative khó song song với một mục tiêu sequence-to-sequence mà không cần một bộ truy hồi bên ngoài. Trong quá trình suy luận, một danh sách các câu trả lời ứng viên được truy hồi sẽ hướng dẫn việc sinh ngôn ngữ một cách tường minh bằng cách loại bỏ các đường giải mã không hợp lệ. Phương pháp được đề xuất đạt được những cải thiện đáng kể trên các phần chia dữ liệu khác nhau trong benchmark Oven-Wiki được đề xuất gần đây. Độ chính xác trên phần chia Entity seen tăng từ 32,7% lên 61,5%. Nó cũng thể hiện hiệu năng vượt trội trên các phần chia unseen và query với một biên độ hai chữ số đáng kể.
chi tiết
trích dẫn
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- AutoVER là gì? AutoVER là một mô hình ngôn ngữ đa phương thức tự hồi quy cho nhận dạng thực thể thị giác, trong đó các câu trả lời phải được định vị tới các thực thể cụ thể trong một cơ sở tri thức lớn.
- Bài báo giải quyết vấn đề nào? Nó giải quyết việc nhận dạng thực thể chi tiết dựa trên ảnh, nơi các mô hình phải phân biệt các thực thể tương tự về mặt thị giác và tránh ảo giác ra các câu trả lời nằm ngoài không gian thực thể hợp lệ.
- Sinh có ràng buộc được tăng cường bằng truy hồi hoạt động như thế nào ở đây? AutoVER truy hồi các thực thể có khả năng, xây dựng một cây tiền tố động từ các ứng viên đó, và ràng buộc việc giải mã sao cho quá trình sinh chỉ đi theo các đường token tên-thực-thể hợp lệ.
- Tại sao sử dụng Contrastive Learning và các negative khó? Mô hình học truy hồi từ truy vấn-sang-thực-thể với các negative khó tương tự về mặt thị giác và tri thức, giúp nó tách biệt các thực thể chia sẻ cùng hình thức hoặc cấu trúc danh mục.
- AutoVER được đánh giá ở đâu? Bài báo đánh giá trên Oven-Wiki và cũng kiểm tra khả năng chuyển giao zero-shot trên một tập con được định vị theo thực thể của A-OKVQA.
Đóng góp chính
- Bài báo giới thiệu AutoVER, một framework tự hồi quy được tăng cường bằng truy hồi để định vị đầu ra của mô hình ngôn ngữ đa phương thức tới các thực thể thị giác ở quy mô Wikipedia.
- Nó tích hợp huấn luyện tương phản từ truy vấn-sang-thực-thể trực tiếp vào mô hình ngôn ngữ đa phương thức, tránh sự phụ thuộc vào một bộ truy hồi bên ngoài riêng biệt.
- Cơ chế giải mã có ràng buộc đảm bảo các câu trả lời được sinh ra được định vị trong các thực thể ứng viên đã được truy hồi, trực tiếp giảm các phần sinh không hợp lệ hoặc không được định vị.
- Việc khai thác negative khó từ độ tương tự thị giác và cấu trúc phân cấp của cơ sở tri thức cải thiện khả năng phân biệt chi tiết giữa các thực thể tương tự về mặt thị giác.
- AutoVER cải thiện đáng kể hiệu năng trên Oven-Wiki, bao gồm việc tăng độ chính xác Entity seen từ 32,7% lên 61,5% trong phép so sánh được báo cáo và vượt trội hơn các baseline PaLI lớn hơn trên các phần chia unseen và query.
Hạn chế và lưu ý
- AutoVER phụ thuộc vào độ bao phủ và chất lượng của cơ sở tri thức thực thể, điều này phù hợp cho nhận dạng thực thể thị giác và làm cho mục tiêu định vị trở nên tường minh.
- Phương pháp truy hồi một tập ứng viên trước khi giải mã có ràng buộc, vì vậy các thực thể rất hiếm hoặc mơ hồ về mặt thị giác vẫn còn thách thức khi truy hồi bỏ sót chúng; bài báo giải quyết trực tiếp điều này bằng các đặc trưng thị giác phía thực thể và huấn luyện negative khó.
- Việc huấn luyện ở quy mô Wikipedia đòi hỏi dữ liệu và tính toán đáng kể, nhưng kết quả là một framework thực tế để biến các cơ sở tri thức lớn thành các mục tiêu nhận dạng thị giác có thể sử dụng được.
- Bài báo vẫn cho thấy một khoảng cách so với hiệu năng của con người cộng với tìm kiếm trên tập đánh giá của con người, đây là một benchmark hữu ích cho tiến bộ trong tương lai chứ không phải là một điểm yếu của cách tiếp cận cốt lõi.
- AutoVER được chuyên biệt hóa cho các câu trả lời được định vị theo thực thể, bổ trợ cho các hệ thống VQA mở rộng hơn khi đầu ra mong muốn cần là một thực thể được đặt tên chính xác.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một đóng góp mạnh mẽ cho nhận dạng đa phương thức được định vị: AutoVER cho thấy rằng truy hồi, học thực thể tương phản, và sinh có ràng buộc có thể khiến các câu trả lời của mô hình ngôn ngữ trở nên chính xác và đáng tin cậy hơn nhiều cho nhận dạng thực thể thị giác ở quy mô Wikipedia.