SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Tóm tắt thông cáo báo chí
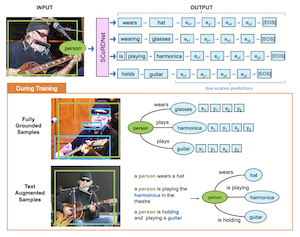
Các nhà nghiên cứu từ Rice University và Adobe Research đã phát triển một hệ thống có tên SCoRD — viết tắt của Subject-Conditional Relation Detection — mà, cho trước một đối tượng cụ thể trong một bức ảnh, tự động xác định mọi thứ mà đối tượng đó đang tương tác, những tương tác đó là gì, và các đối tượng khác nằm ở đâu trong ảnh. Thay vì cố gắng vạch ra mọi quan hệ khả dĩ giữa mọi đối tượng trong một cảnh, điều nhanh chóng trở nên bất khả thi, hệ thống tập trung vào một chủ thể được chọn duy nhất và liệt kê đầy đủ chỉ những kết nối liên quan của nó. Nhóm đã xây dựng mô hình của họ, SCoRDNet, như một bộ giải mã chuỗi tự hồi quy xuất ra các cặp quan hệ-đối tượng cùng với tọa độ hộp giới hạn dưới dạng một dòng token, và họ đã thiết kế một benchmark dựa trên bộ dữ liệu Open Images được tạo ra một cách đặc biệt sao cho dữ liệu huấn luyện và kiểm thử có thống kê quan hệ không khớp nhau — khiến mô hình khó có thể chỉ đơn giản ghi nhớ các mẫu phổ biến. Một phát hiện quan trọng là hiệu năng của hệ thống trên các loại quan hệ hiếm hoặc chưa từng thấy trước đây được cải thiện đáng kể khi việc huấn luyện được bổ sung bằng các bộ ba quan hệ nhiễu được trích xuất tự động từ các chú thích ảnh, ngay cả khi các chú thích đó hoàn toàn không kèm chú thích hộp giới hạn nào. Trên các quan hệ mà mô hình cơ sở chưa bao giờ gặp trong quá trình huấn luyện, phiên bản tăng cường bằng văn bản đạt recall 33.8% cho các cặp quan hệ-đối tượng và 26.75% cho vị trí hộp của chúng, so với gần như bằng không đối với baseline không được hỗ trợ. Công trình có ý nghĩa bởi nó mang lại một con đường có khả năng mở rộng hơn hướng tới phát hiện quan hệ với từ vựng mở: thay vì đòi hỏi các bộ dữ liệu được chú thích đầy đủ tốn kém cho mọi tương tác khả dĩ, cách tiếp cận này gợi ý rằng các bộ sưu tập ảnh có chú thích lớn đã có sẵn trên internet có thể mở rộng đáng kể những gì mà các hệ thống như vậy có thể nhận diện và định vị.
tóm tắt
Chúng tôi đề xuất Subject-Conditional Relation Detection SCoRD, trong đó với điều kiện cho trước một chủ thể đầu vào, mục tiêu là dự đoán tất cả các quan hệ của nó với các đối tượng khác trong một cảnh cùng với vị trí của chúng. Dựa trên bộ dữ liệu Open Images, chúng tôi đề xuất một benchmark đầy thách thức OIv6-SCoRD sao cho các phần tách huấn luyện và kiểm thử có sự dịch chuyển phân phối về mặt thống kê xuất hiện của các bộ ba $\langle$chủ thể, quan hệ, đối tượng$\rangle$. Để giải quyết vấn đề này, chúng tôi đề xuất một mô hình tự hồi quy mà cho trước một chủ thể, nó dự đoán các quan hệ, đối tượng và vị trí đối tượng của chủ thể đó bằng cách biểu diễn đầu ra này như một chuỗi token. Trước tiên, chúng tôi cho thấy rằng các phương pháp dự đoán scene-graph trước đây không tạo ra được một liệt kê các cặp quan hệ-đối tượng đầy đủ khi có điều kiện trên một chủ thể trên benchmark này. Cụ thể, chúng tôi đạt được recall@3 là 83.8% cho các dự đoán quan hệ-đối tượng của mình so với 49.75% đạt được bởi một bộ phát hiện scene graph gần đây. Sau đó, chúng tôi cho thấy khả năng khái quát hóa được cải thiện trên cả dự đoán quan hệ-đối tượng và hộp đối tượng bằng cách tận dụng trong quá trình huấn luyện các cặp quan hệ-đối tượng thu được tự động từ các chú thích văn bản và đối với chúng không có sẵn chú thích hộp đối tượng. Cụ thể, đối với các bộ ba $\langle$chủ thể, quan hệ, đối tượng$\rangle$ mà không có sẵn vị trí đối tượng trong quá trình huấn luyện, chúng tôi có thể đạt được recall@3 là 33.80% cho các cặp quan hệ-đối tượng và 26.75% cho vị trí hộp của chúng.
chi tiết
trích dẫn
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- SCoRD là gì? SCoRD là một tác vụ phát hiện quan hệ có điều kiện theo chủ thể, trong đó một mô hình nhận một chủ thể được chọn trong một ảnh và dự đoán các quan hệ, các đối tượng liên quan, và vị trí đối tượng của chủ thể đó.
- SCoRD khác với việc tạo scene graph đầy đủ như thế nào? Thay vì dự đoán mọi quan hệ giữa mọi đối tượng, SCoRD tập trung vào việc mô tả đầy đủ các quan hệ của một chủ thể được truy vấn, điều thường thực tế hơn cho các ứng dụng hạ nguồn.
- SCoRDNet là gì? SCoRDNet là một mô hình thị giác-ngôn ngữ tự hồi quy biểu diễn các dự đoán quan hệ-đối tượng và tọa độ hộp giới hạn dưới dạng một chuỗi token.
- Tại sao dùng dữ liệu tăng cường bằng văn bản? Các bộ ba quan hệ-đối tượng dẫn xuất từ chú thích cung cấp giám sát có khả năng mở rộng cho các quan hệ hiếm hoặc chưa từng thấy, ngay cả khi các chú thích không bao gồm chú thích hộp đối tượng.
- Benchmark OIv6-SCoRD kiểm tra điều gì? Benchmark tạo ra sự dịch chuyển phân phối giữa huấn luyện và kiểm thử trong các bộ ba chủ thể-quan hệ-đối tượng, khiến nó trở thành một bài kiểm tra mạnh về khả năng khái quát hóa vượt ra ngoài thống kê quan hệ được ghi nhớ.
Đóng góp chính
- Bài báo định nghĩa Subject-Conditional Relation Detection như một giải pháp thay thế có trọng tâm cho việc tạo scene graph đầy đủ trong việc mô tả các quan hệ của một đối tượng được chỉ định.
- Nó giới thiệu OIv6-SCoRD, một benchmark được thiết kế để kiểm tra căng thẳng việc phát hiện quan hệ dưới sự dịch chuyển phân phối trong thống kê quan hệ-đối tượng.
- SCoRDNet biểu diễn dự đoán quan hệ, đối tượng và định vị như một bài toán giải mã token thống nhất, cho phép xử lý giám sát có định vị và không có định vị trong cùng một mô hình.
- Bài báo cho thấy rằng việc huấn luyện tăng cường bằng văn bản từ các chú thích cải thiện đáng kể khả năng khái quát hóa sang các cặp quan hệ-đối tượng ít được đại diện và chưa từng thấy.
- SCoRDNet vượt trội các phiên bản scene graph được điều chỉnh theo điều kiện chủ thể trong dự đoán quan hệ-đối tượng và chứng minh rằng các chú thích không có định vị có thể cải thiện cả dự đoán quan hệ lẫn định vị đối tượng.
Hạn chế và lưu ý
- SCoRD giả định rằng một chủ thể và hộp của nó được cung cấp làm đầu vào, điều giữ cho tác vụ có trọng tâm và khiến nó phù hợp với các ứng dụng nơi người dùng hoặc một bộ phát hiện thượng nguồn xác định đối tượng quan tâm.
- Các bộ ba quan hệ dẫn xuất từ chú thích thì nhiễu và thường thiếu hộp đối tượng, nhưng bài báo biến tín hiệu yếu này thành một thế mạnh bằng cách cho thấy rằng nó vẫn cải thiện khả năng khái quát hóa khi kết hợp với dữ liệu có định vị.
- Phương pháp được đánh giá trên một benchmark dẫn xuất từ Open Images và các nguồn chú thích như COCO và Conceptual Captions, để lại các bộ sưu tập ảnh thế giới mở rộng hơn như những bài kiểm tra tiếp theo tự nhiên.
- SCoRDNet dự đoán các hộp thông qua giải mã chuỗi thay vì tinh chỉnh hộp chuyên biệt, điều để ngỏ chỗ cho các kết hợp tương lai với các mô-đun định vị mạnh hơn.
- Tác vụ tập trung vào các quan hệ lấy chủ thể làm trung tâm thay vì các scene graph hoàn chỉnh, mang lại một công thức thực tế và có khả năng mở rộng trong khi bổ trợ cho các hệ thống tạo đồ thị rộng hơn.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một bước tiến mạnh mẽ hướng tới sự hiểu biết quan hệ thị giác có khả năng mở rộng: SCoRD tái định hình việc phát hiện quan hệ xoay quanh một chủ thể được truy vấn, và SCoRDNet cho thấy rằng giám sát chú thích chi phí thấp có thể mở rộng một cách có ý nghĩa những cặp quan hệ-đối tượng mà một mô hình có thể nhận diện và định vị.