Improving Progressive Generation with Decomposable Flow Matching
新闻稿摘要
莱斯大学和 Snap Inc. 的研究人员开发了一种生成高分辨率图像和视频的新方法,它在提升质量的同时避免了多阶段生成系统通常伴随的复杂性。这项名为可分解流匹配(Decomposable Flow Matching,DFM)的工作应对了 AI 图像合成中一个已知的挑战:高效生成精细的视觉细节需要将任务拆分为从粗到细的步骤,但现有的做法通常要求为每个阶段配备单独的模型、自定义的扩散过程,或在阶段之间进行繁琐的衔接。DFM 通过将一种名为流匹配(Flow Matching)的标准技术独立地应用到多尺度图像表示的每个层级——本质上是一个把图像分离为细节逐层递增的层次的拉普拉斯金字塔——而始终使用单个共享模型,从而绕开了这些复杂性。在训练中,系统通过为每个阶段采样不同的噪声水平来模拟渐进式生成过程;在推理时,一个简单的调度器从粗到细依次推进各个阶段。在标准的 ImageNet-1K 基准 512 像素分辨率上进行测试,在相同的训练计算量下,DFM 将一项名为 FDD 的关键质量指标相较普通流匹配降低了 35%,相较表现最佳的竞争多阶段方法降低了 26%。研究人员还将 DFM 应用于对 FLUX(一个大型商用级图像生成模型)的微调,发现它比标准微调更快地收敛到目标图像分布,将 FID 分数降低了约 29%。这项工作的意义主要在于其简洁性:它通过对现有训练流程的极少改动带来了有意义的质量提升,而非要求一套全新的架构或单独的模型级联。
摘要
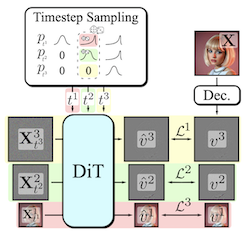
生成高维视觉模态是一项计算密集型任务。一种常见的解决方案是渐进式生成(progressive generation),即以从粗到细的频谱自回归方式合成输出。尽管扩散模型受益于去噪本身从粗到细的特性,显式的多阶段架构却很少被采用。这类架构增加了整体方法的复杂度,带来了对自定义扩散表述、依赖分解的阶段转换、临时采样器或模型级联的需求。我们的贡献——可分解流匹配(Decomposable Flow Matching,DFM)——是一个用于视觉媒体渐进式生成的简单而有效的框架。DFM 在用户定义的多尺度表示(如拉普拉斯金字塔,Laplacian pyramid)的每个层级上独立地应用流匹配(Flow Matching)。如我们的实验所示,我们的方法改善了图像和视频的视觉质量,相较以往的多阶段框架取得了更优的结果。在 Imagenet-1k 512px 上,在相同的训练计算量下,DFM 在 FDD 分数上相较基础架构提升了 35.2%,相较表现最佳的基线提升了 26.4%。当应用于诸如 FLUX 等大型模型的微调时,DFM 展现出向训练分布更快的收敛速度。至关重要的是,所有这些优势都是用单个模型、简洁的架构以及对现有训练流程的极少改动实现的。
详情
引用
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 什么是可分解流匹配(Decomposable Flow Matching),它解决了什么问题?DFM 是一个渐进式生成框架,它在多尺度表示的各个层级上独立地应用流匹配(Flow Matching),在无需模型级联或自定义扩散过程的情况下改善了从粗到细的图像和视频合成。
- DFM 如何渐进式地生成样本?它将视觉数据分解为诸如拉普拉斯金字塔的若干阶段,为每个阶段分配各自的流时间步,并使用一个采样器将各阶段从粗略结构推进到精细细节。
- 为什么 DFM 比以往许多渐进式生成方法更简单?它保持单个共享模型和标准的流匹配表述,避免了为每个阶段配备单独模型、专门的采样器以及复杂的转换机制。
- DFM 在图像生成基准上的表现如何?在 ImageNet-1K 的 512px 和 1024px 上,DFM 在本文报告的主要指标和引导设置上均优于 Flow Matching、级联基线以及 Pyramidal Flow。
- DFM 是否有助于大规模模型的微调?是的,在应用于 FLUX 微调时,DFM 在相同的训练计算量下取得了优于标准微调的 FID、FDD 和 CLIP 相似度,表现出向目标分布更快的收敛。
主要贡献
- 本文提出了流匹配(Flow Matching)的一种简单的多尺度扩展,它将视觉生成转变为一个可分解的从粗到细的过程,同时保持单个共享生成器。
- DFM 支持用户定义的分解方式,本文采用拉普拉斯金字塔,同时指出小波、DCT、Fourier 或多尺度自编码器分解都是自然的替代方案。
- 该方法包含对训练时间步分布、采样阈值、各阶段采样步数、掩码、分解选择以及计算分配策略的详细分析。
- 实验在 ImageNet-1K 图像生成和 Kinetics-700 视频生成上展示了强劲结果,在大多数设置下取得了本文渐进式生成基线中报告的最佳数值。
- FLUX 微调实验表明,DFM 能够以对训练流程的极少改动改善大型生成模型的适配。
局限与注意事项
- DFM 引入了额外的训练与采样超参数,但本文提供了大量消融实验和实用指导,表明稳定的设置可在多个实验之间迁移。
- 该框架的性能取决于在低频结构与高频细节之间取得平衡,因此未来工作可以改进自动调度策略;当前结果已经表明这种平衡能够带来巨大的质量提升。
- 主要实现使用拉普拉斯分解,这使得 DCT、小波和多尺度自编码器等其他分解方式成为有前景的扩展,而非核心表述的弱点。
- 大型模型实验聚焦于将 FLUX 微调到目标分布,而非声称在每一种部署设置下都能改进原始的前沿模型,这使结论范围明确,同时仍具实用价值。
- DFM 最好被视为一个用于更好渐进式生成的训练时框架,而非独立的纯推理加速器,其简洁性使它与未来在更快采样和部署方面的系统工作形成互补。
如何理解这一结果
这篇论文最好被理解为对渐进式视觉生成一项强有力而优雅的贡献:DFM 用单个流匹配(Flow Matching)模型捕捉了从粗到细合成的优势,在多个基准上改善了图像与视频质量,并为更好地微调大型生成系统提供了一条实用路径。