新闻稿摘要
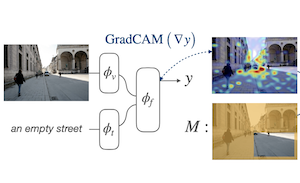
莱斯大学和 Adobe Research 的研究人员开发了一种新的训练技术,可以改善 AI 视觉-语言模型在给定文本描述时定位图像中物体和区域的能力。他们解决的问题是:虽然在互联网规模的图像-文本对上训练的大型模型可以宽泛地将词语与图像区域匹配,但它们并未被显式地教导如何精确定位事物。该团队的方法名为 Attention Mask Consistency(AMC),其工作原理是观察模型在判断图像与文本是否匹配时自然产生的基于梯度的“解释热力图”,然后在训练期间,每当这些热力图高亮了图像中错误的部分(即人类标注区域之外的区域)时,就对模型进行惩罚。这种惩罚采用间隔损失的形式,促使模型将热力图的能量集中在标注区域内部而非外部。关键在于,该方法不需要将目标检测器作为中间环节(大多数竞争方法都是这样做的),并且它可以叠加在现有模型之上——在本例中是 ALBEF——而无需从头重新训练。在 Flickr30k 视觉接地基准上,使用 AMC 训练的模型达到了 86.49% 的准确率,比在相当监督水平下此前发表的最佳结果提高了五个多百分点,并且它还在 RefCOCO+ 指代表达数据集上创造了新的纪录。这项工作之所以重要,是因为它提供了一条相对轻量的途径,无需训练目标检测器这一昂贵的基础设施,即可改善视觉-语言模型中的空间推理能力。
摘要
我们提出了一种基于间隔(margin)的损失,用于调优联合视觉-语言模型,使其基于梯度的解释与人类为相对较小的接地(grounding)数据集提供的区域级标注保持一致。我们将这一目标称为 Attention Mask Consistency(AMC),并证明它比以往依赖视觉-语言模型为目标检测器的输出打分的方法产生了更优的视觉接地结果。特别地,在标准视觉-语言建模目标之上使用 AMC 训练的模型,在 Flickr30k 视觉接地基准上取得了 86.49% 的最先进准确率,与在相同监督水平下训练的最佳先前模型相比,绝对提升了 5.38%。我们的方法在公认的指代表达理解基准上也表现极佳,在 RefCOCO+ 的 easy 测试上取得 80.34% 的准确率,在困难划分上取得 64.55%。AMC 高效、易于实现且具有通用性,因为它可以被任何视觉-语言模型采用,并可以使用任何类型的区域标注。
详情
引用
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}