CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Zusammenfassung der Pressemitteilung
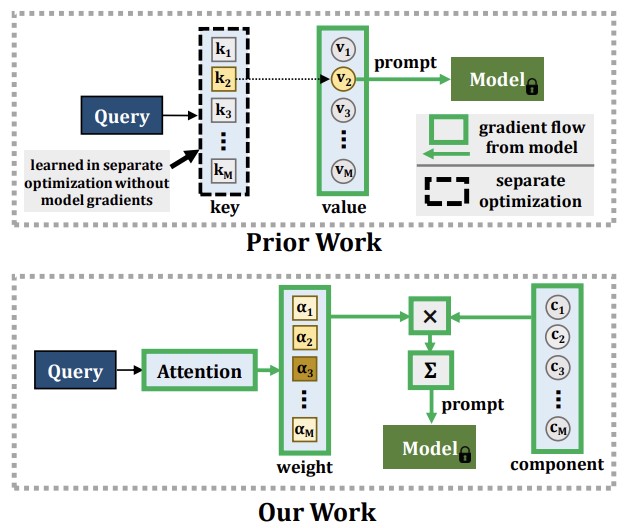
Forschende von Georgia Tech, dem MIT-IBM Watson AI Lab, der Rice University und von IBM Research haben einen neuen Ansatz für ein hartnäckiges Problem des maschinellen Lernens entwickelt: Wenn ein KI-Modell neue Dinge lernt, neigt es dazu, das bereits Gelernte zu vergessen, ein Phänomen, das als katastrophales Vergessen bezeichnet wird. Bestehende Behelfslösungen bestehen typischerweise darin, alte Trainingsdaten zu speichern und sie in künftigen Trainingssitzungen erneut abzuspielen, doch dieser Ansatz wirft Datenschutzbedenken auf und verbraucht Speicher. Neuere Methoden nutzten eine Technik namens Prompting – das Einspeisen kleiner instruktiver Einbettungen in ein vortrainiertes Vision-Transformer-Modell –, um diese Probleme zu umgehen, doch jene Ansätze hatten eine grundlegende Einschränkung: Der Mechanismus zur Auswahl des anzuwendenden Prompts konnte nicht auf vollständig verbundene, durchgängige (end-to-end) Weise zusammen mit dem Rest des Systems trainiert werden, was die Fähigkeit des Modells begrenzte, wirklich neue Informationen aufzunehmen. Das neue System des Teams namens CODA-Prompt ersetzt den festen Pool von Prompts durch eine Menge lernbarer "Prompt-Komponenten", die mithilfe aufmerksamkeitsbasierter Gewichte, die von jedem Eingabebild abhängen, zusammengemischt werden, sodass das gesamte System in einem einzigen Optimierungsdurchlauf durchgängig trainiert werden kann. Die Methode friert außerdem zuvor gelernte Komponenten ein, wenn neue Aufgaben angegangen werden, und wendet eine mathematische Strafe an, um zu verhindern, dass sich Komponenten gegenseitig stören. In Benchmark-Tests auf Standard-Bildklassifikationsdatensätzen übertraf CODA-Prompt die zuvor führende Methode DualPrompt um bis zu 4,5 Prozentpunkte in der durchschnittlichen Genauigkeit und hielt sich auch in einem realistischeren Test gut, der sowohl Veränderungen bei neuen Kategorien als auch Stilverschiebungen gleichzeitig vermischte – die Art von zusammengesetzten Verteilungsverschiebungen, die reale Einsatzbedingungen widerspiegeln.
Zusammenfassung
Computer-Vision-Modelle leiden unter einem Phänomen, das als katastrophales Vergessen bekannt ist, wenn sie neuartige Konzepte aus sich kontinuierlich verschiebenden Trainingsdaten lernen. Typische Lösungen für dieses Problem des kontinuierlichen Lernens erfordern ein umfangreiches Wiederholen zuvor gesehener Daten, was die Speicherkosten erhöht und den Datenschutz verletzen kann. In jüngster Zeit haben großmaßstäblich vortrainierte Vision-Transformer-Modelle Prompting-Ansätze als Alternative zum Daten-Rehearsal ermöglicht. Diese Ansätze stützen sich auf einen Schlüssel-Abfrage-Mechanismus zur Erzeugung von Prompts und haben sich in der gut etablierten, rehearsal-freien Umgebung des kontinuierlichen Lernens als hochgradig resistent gegen katastrophales Vergessen erwiesen. Der Schlüsselmechanismus dieser Methoden wird jedoch nicht durchgängig (end-to-end) mit der Aufgabensequenz trainiert. Unsere Experimente zeigen, dass dies zu einer Verringerung ihrer Plastizität führt, was die Genauigkeit bei neuen Aufgaben beeinträchtigt, sowie zu einer Unfähigkeit, von erweiterter Parameterkapazität zu profitieren. Stattdessen schlagen wir vor, eine Menge von Prompt-Komponenten zu lernen, die mit eingabeabhängigen Gewichten zusammengesetzt werden, um eingabeabhängige Prompts zu erzeugen, was zu einem neuartigen, aufmerksamkeitsbasierten End-to-End-Schlüssel-Abfrage-Schema führt. Unsere Experimente zeigen, dass wir die derzeitige SOTA-Methode DualPrompt auf etablierten Benchmarks um bis zu 4,5 % in der durchschnittlichen finalen Genauigkeit übertreffen. Wir übertreffen den Stand der Technik außerdem um bis zu 4,4 % Genauigkeit auf einem Benchmark für kontinuierliches Lernen, der sowohl klasseninkrementelle als auch domäneninkrementelle Aufgabenverschiebungen enthält, was vielen praktischen Szenarien entspricht. Unser Code ist verfügbar unter https://github.com/GT-RIPL/CODA-Prompt
Details
Zitation
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}