CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Resumo do comunicado de imprensa
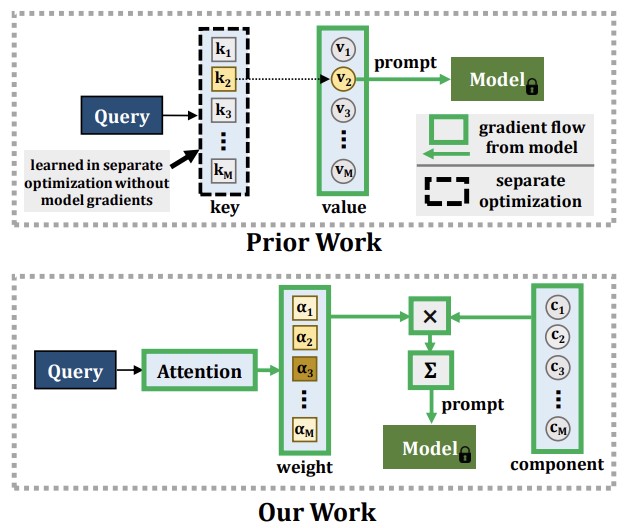
Pesquisadores da Georgia Tech, do MIT-IBM Watson AI Lab, da Rice University e da IBM Research desenvolveram uma nova abordagem para um problema persistente em aprendizado de máquina: quando um modelo de IA aprende coisas novas, ele tende a esquecer o que já sabia, um fenômeno chamado esquecimento catastrófico. As soluções alternativas existentes normalmente envolvem armazenar dados de treinamento antigos e repeti-los em sessões de treinamento futuras, mas essa abordagem levanta preocupações de privacidade e consome memória. Métodos mais recentes usaram uma técnica chamada prompting — alimentar pequenos embeddings instrutivos em um modelo vision transformer pré-treinado — para contornar esses problemas, mas essas abordagens tinham uma limitação fundamental: o mecanismo usado para selecionar qual prompt aplicar não podia ser treinado de forma totalmente conectada e de ponta a ponta junto com o restante do sistema, o que limitava a capacidade do modelo de absorver informações genuinamente novas. O novo sistema da equipe, chamado CODA-Prompt, substitui o conjunto fixo de prompts por um conjunto de "componentes de prompt" aprendíveis que são combinados usando pesos baseados em atenção condicionados a cada imagem de entrada, permitindo que todo o sistema seja treinado de ponta a ponta em um único passo de otimização. O método também congela os componentes aprendidos anteriormente ao enfrentar novas tarefas e aplica uma penalidade matemática para evitar que os componentes interfiram entre si. Em testes de benchmark em conjuntos de dados padrão de classificação de imagens, o CODA-Prompt superou o método líder anterior, DualPrompt, em até 4,5 pontos percentuais de acurácia média, e também se saiu bem em um teste mais realista que misturava simultaneamente mudanças de novas categorias e de estilo — o tipo de mudanças de distribuição compostas que refletem as condições reais de implantação.
resumo
Modelos de visão computacional sofrem de um fenômeno conhecido como esquecimento catastrófico ao aprender novos conceitos a partir de dados de treinamento que mudam continuamente. As soluções típicas para esse problema de aprendizado contínuo exigem uma extensa repetição de dados vistos anteriormente, o que aumenta os custos de memória e pode violar a privacidade dos dados. Recentemente, o surgimento de modelos vision transformer pré-treinados em larga escala viabilizou abordagens de prompting como alternativa à repetição de dados. Essas abordagens dependem de um mecanismo de chave-consulta (key-query) para gerar prompts e mostraram-se altamente resistentes ao esquecimento catastrófico no cenário consolidado de aprendizado contínuo sem repetição. No entanto, o mecanismo de chave desses métodos não é treinado de ponta a ponta com a sequência de tarefas. Nossos experimentos mostram que isso leva a uma redução em sua plasticidade, sacrificando assim a acurácia em novas tarefas, e à incapacidade de se beneficiar de uma capacidade ampliada de parâmetros. Em vez disso, propomos aprender um conjunto de componentes de prompt que são montados com pesos condicionados à entrada para produzir prompts condicionados à entrada, resultando em um novo esquema de chave-consulta de ponta a ponta baseado em atenção. Nossos experimentos mostram que superamos o método SOTA atual, DualPrompt, em benchmarks consolidados em até 4,5% na acurácia final média. Também superamos o estado da arte em até 4,4% de acurácia em um benchmark de aprendizado contínuo que contém tanto mudanças de tarefa incrementais por classe quanto incrementais por domínio, correspondendo a muitos cenários práticos. Nosso código está disponível em https://github.com/GT-RIPL/CODA-Prompt
detalhes
citação
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}