CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Resumen de prensa
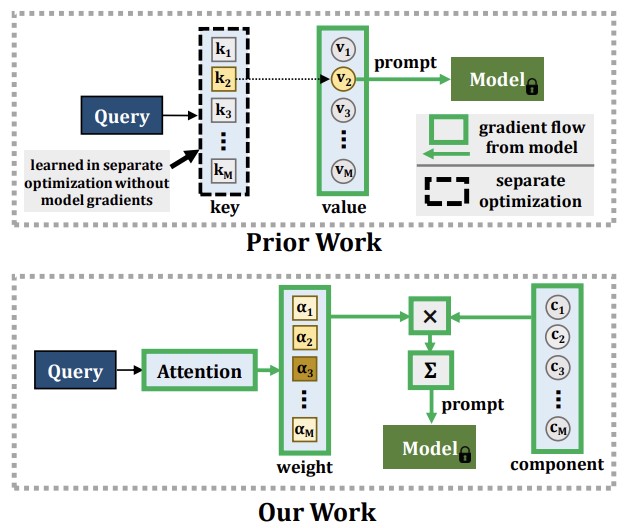
Investigadores de Georgia Tech, MIT-IBM Watson AI Lab, la Universidad Rice e IBM Research han desarrollado un nuevo enfoque para un problema persistente en el aprendizaje automático: cuando un modelo de IA aprende cosas nuevas, tiende a olvidar lo que ya sabía, un fenómeno llamado olvido catastrófico. Las soluciones existentes suelen implicar almacenar datos de entrenamiento antiguos y reproducirlos durante sesiones de entrenamiento futuras, pero ese enfoque plantea preocupaciones de privacidad y consume memoria. Métodos más recientes usaron una técnica llamada prompting — alimentando pequeños embeddings instructivos a un modelo de vision transformer preentrenado — para esquivar esos problemas, pero esos enfoques tenían una limitación fundamental: el mecanismo usado para seleccionar qué prompt aplicar no podía entrenarse de forma totalmente conectada, de extremo a extremo, junto con el resto del sistema, lo que limitaba la capacidad del modelo de absorber información genuinamente nueva. El nuevo sistema del equipo, llamado CODA-Prompt, reemplaza el conjunto fijo de prompts por un conjunto de "componentes de prompt" aprendibles que se mezclan usando pesos basados en atención condicionados a cada imagen de entrada, permitiendo que todo el sistema se entrene de extremo a extremo en una única pasada de optimización. El método también congela los componentes aprendidos previamente al abordar nuevas tareas y aplica una penalización matemática para evitar que los componentes interfieran entre sí. En pruebas de benchmark sobre conjuntos de datos estándar de clasificación de imágenes, CODA-Prompt superó al método líder anterior, DualPrompt, hasta en 4,5 puntos porcentuales en precisión promedio, y también se mantuvo bien en una prueba más realista que mezclaba simultáneamente cambios de nuevas categorías y de cambios de estilo — el tipo de cambios de distribución compuestos que reflejan las condiciones de despliegue del mundo real.
resumen
Los modelos de visión por computadora sufren un fenómeno conocido como olvido catastrófico al aprender conceptos novedosos a partir de datos de entrenamiento que cambian continuamente. Las soluciones típicas para este problema de aprendizaje continuo requieren un repaso (rehearsal) extensivo de los datos vistos previamente, lo que aumenta los costos de memoria y puede violar la privacidad de los datos. Recientemente, la aparición de modelos de vision transformer preentrenados a gran escala ha permitido enfoques de prompting como alternativa al repaso de datos. Estos enfoques se basan en un mecanismo de clave-consulta (key-query) para generar prompts y se ha descubierto que son altamente resistentes al olvido catastrófico en el bien establecido escenario de aprendizaje continuo sin repaso. Sin embargo, el mecanismo de clave de estos métodos no se entrena de extremo a extremo con la secuencia de tareas. Nuestros experimentos muestran que esto conduce a una reducción de su plasticidad, sacrificando así la precisión en tareas nuevas, y a la incapacidad de beneficiarse de una capacidad de parámetros ampliada. En su lugar, proponemos aprender un conjunto de componentes de prompt que se ensamblan con pesos condicionados a la entrada para producir prompts condicionados a la entrada, dando como resultado un novedoso esquema de clave-consulta basado en atención y de extremo a extremo. Nuestros experimentos muestran que superamos al método actual SOTA DualPrompt en benchmarks establecidos hasta en un 4,5% en precisión final promedio. También superamos al estado del arte hasta en un 4,4% de precisión en un benchmark de aprendizaje continuo que contiene cambios de tarea tanto incrementales en clases como incrementales en dominio, correspondientes a muchos escenarios prácticos. Nuestro código está disponible en https://github.com/GT-RIPL/CODA-Prompt
detalles
cita
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}