CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
新闻稿摘要
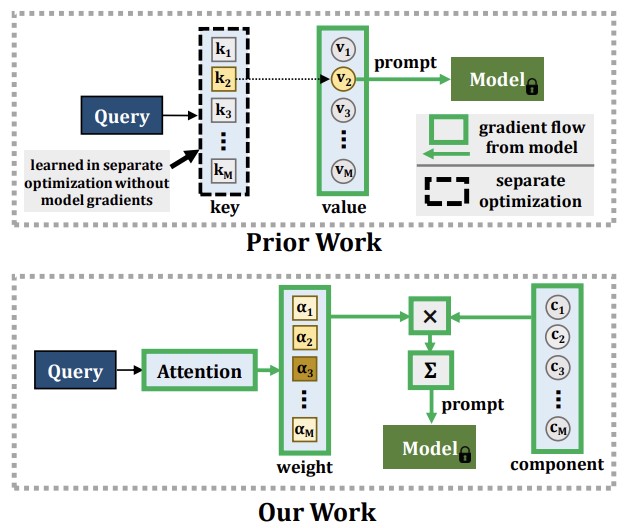
来自佐治亚理工学院、MIT-IBM Watson AI Lab、莱斯大学和 IBM Research 的研究人员针对机器学习中一个长期存在的问题开发了一种新方法:当 AI 模型学习新事物时,它往往会忘记已经掌握的内容,这种现象称为灾难性遗忘。现有的变通方案通常涉及存储旧的训练数据,并在未来的训练过程中重放它们,但这种方法引发隐私担忧并占用内存。较新的方法使用一种称为提示的技术——向预训练的视觉 Transformer 模型输入小的指令性嵌入——以规避这些问题,但这些方法有一个根本局限:用于选择应用哪个提示的机制无法与系统其余部分一起以完全连接、端到端的方式训练,从而限制了模型吸收真正新信息的能力。团队的新系统名为 CODA-Prompt,它用一组可学习的“提示组件”取代了固定的提示池,这些组件通过基于每张输入图像的注意力权重混合在一起,使整个系统能够在单次优化过程中端到端训练。该方法在处理新任务时还会冻结此前学到的组件,并应用数学惩罚以防止组件相互干扰。在标准图像分类数据集的基准测试中,CODA-Prompt 在平均准确率上以高达 4.5 个百分点优于此前领先的方法 DualPrompt,并且在一个更贴近现实、同时混合了新类别和风格偏移变化的测试中也表现良好——这类复合分布偏移反映了真实世界的部署条件。
摘要
计算机视觉模型在从持续变化的训练数据中学习新概念时,会遭遇一种称为灾难性遗忘(catastrophic forgetting)的现象。针对这一持续学习问题的典型解决方案需要对以往见过的数据进行大量复演(rehearsal),这增加了内存成本,并可能违反数据隐私。最近,大规模预训练视觉 Transformer 模型的出现,使得提示(prompting)方法成为数据复演的一种替代方案。这些方法依赖键-查询(key-query)机制来生成提示,并已被发现在公认的无复演持续学习设定中高度抵抗灾难性遗忘。然而,这些方法的关键机制并未与任务序列进行端到端训练。我们的实验表明,这会降低其可塑性,从而牺牲新任务的准确率,且无法从扩展的参数容量中获益。我们转而提出学习一组提示组件,这些组件通过输入条件权重进行组装以生成输入条件提示,从而形成一种新颖的基于注意力的端到端键-查询方案。我们的实验表明,在公认的基准上,我们以高达 4.5% 的平均最终准确率优于当前的 SOTA 方法 DualPrompt。我们还在一个同时包含类增量和域增量任务偏移的持续学习基准上,以高达 4.4% 的准确率优于现有最优水平,这对应了许多实际场景。我们的代码可在 https://github.com/GT-RIPL/CODA-Prompt 获取。
详情
引用
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}