CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
보도 자료 요약
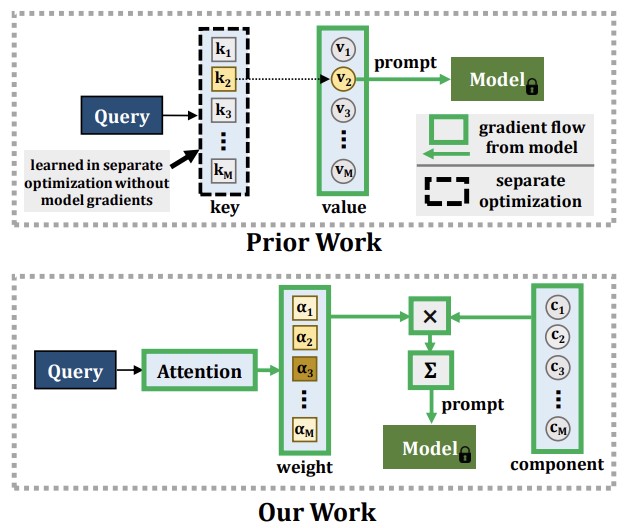
조지아 공대, MIT-IBM Watson AI Lab, 라이스 대학교, IBM Research의 연구자들은 기계 학습의 지속적인 문제에 대한 새로운 접근법을 개발했다: AI 모델이 새로운 것을 학습할 때, 이미 알고 있던 것을 잊어버리는 경향이 있는데, 이 현상을 catastrophic forgetting(파국적 망각)이라 한다. 기존의 우회책들은 일반적으로 오래된 학습 데이터를 저장하고 향후 학습 세션 동안 그것을 재생하는 것을 포함하지만, 그 접근법은 프라이버시 우려를 제기하고 메모리를 잡아먹는다. 더 최근의 방법들은 프롬프팅이라는 기법(작은 지시적 임베딩을 사전학습된 vision transformer 모델에 공급하는 것)을 사용하여 그러한 문제를 피했지만, 이러한 접근법들은 근본적인 한계가 있었다: 어떤 프롬프트를 적용할지 선택하는 데 사용되는 메커니즘이 시스템의 나머지 부분과 함께 완전히 연결된 종단간 방식으로 학습될 수 없어서, 진정으로 새로운 정보를 흡수하는 모델의 능력을 제한했다. CODA-Prompt라는 연구팀의 새로운 시스템은 고정된 프롬프트 풀을, 각 입력 이미지에 조건화된 attention 기반 가중치를 사용하여 함께 혼합되는 일련의 학습 가능한 "프롬프트 구성 요소"로 대체하여, 전체 시스템이 단일 최적화 과정에서 종단간으로 학습될 수 있게 한다. 이 방법은 또한 새로운 작업을 다룰 때 이전에 학습된 구성 요소를 동결하고, 구성 요소들이 서로 간섭하지 않도록 수학적 페널티를 적용한다. 표준 이미지 분류 데이터셋에 대한 벤치마크 테스트에서, CODA-Prompt는 이전의 선도적 방법인 DualPrompt를 평균 정확도에서 최대 4.5 퍼센트 포인트까지 능가했으며, 새로운 범주와 스타일 변화를 동시에 섞은 더 현실적인 테스트(실제 배포 조건을 반영하는 종류의 복합 분포 변화)에서도 잘 견뎌냈다.
초록
컴퓨터 비전 모델은 지속적으로 변화하는 학습 데이터로부터 새로운 개념을 학습할 때 catastrophic forgetting(파국적 망각)으로 알려진 현상을 겪는다. 이 continual learning 문제에 대한 전형적인 해결책은 이전에 본 데이터의 광범위한 반복 학습을 요구하는데, 이는 메모리 비용을 증가시키고 데이터 프라이버시를 침해할 수 있다. 최근, 대규모 사전학습 vision transformer 모델의 등장은 데이터 반복 학습의 대안으로 프롬프팅 접근법을 가능하게 했다. 이러한 접근법들은 프롬프트를 생성하기 위해 key-query 메커니즘에 의존하며, 잘 확립된 반복 학습 없는(rehearsal-free) continual learning 설정에서 catastrophic forgetting에 매우 강한 것으로 밝혀졌다. 그러나 이러한 방법들의 핵심 메커니즘은 작업 시퀀스와 종단간(end-to-end)으로 학습되지 않는다. 우리의 실험은 이것이 그들의 가소성(plasticity) 감소로 이어져 새로운 작업 정확도를 희생시키고, 확장된 파라미터 용량으로부터 이득을 얻지 못하게 함을 보여준다. 우리는 대신 입력 조건적 가중치로 조립되어 입력 조건적 프롬프트를 생성하는 일련의 프롬프트 구성 요소를 학습할 것을 제안하며, 이는 새로운 attention 기반 종단간 key-query 방식을 낳는다. 우리의 실험은 우리가 확립된 벤치마크에서 현재 SOTA 방법인 DualPrompt를 평균 최종 정확도에서 최대 4.5%까지 능가함을 보여준다. 또한 우리는 class-incremental 및 domain-incremental 작업 변화를 모두 포함하는, 많은 실용적 설정에 해당하는 continual learning 벤치마크에서 최첨단 기술을 정확도에서 최대 4.4%까지 능가한다. 우리의 코드는 https://github.com/GT-RIPL/CODA-Prompt 에서 이용 가능하다.
세부 정보
인용
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}