CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Sintesi del comunicato stampa
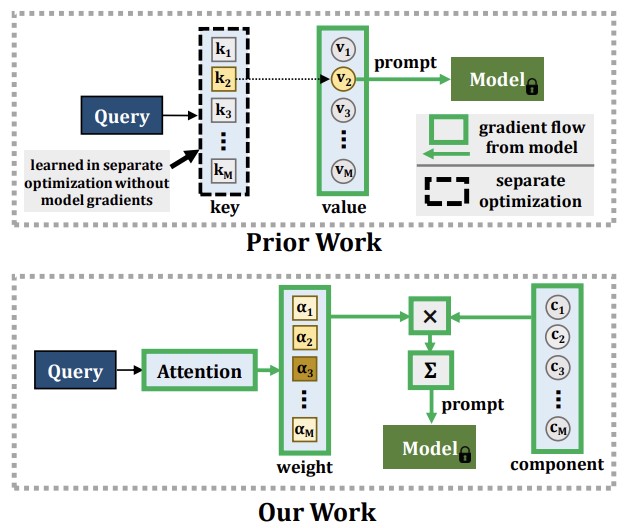
Ricercatori di Georgia Tech, MIT-IBM Watson AI Lab, Rice University e IBM Research hanno sviluppato un nuovo approccio a un problema persistente nell'apprendimento automatico: quando un modello di IA apprende cose nuove, tende a dimenticare ciò che già sapeva, un fenomeno chiamato oblio catastrofico. Le soluzioni esistenti prevedono in genere di conservare i vecchi dati di addestramento e di riproporli nelle sessioni di addestramento successive, ma questo approccio solleva problemi di privacy e consuma memoria. I metodi più recenti hanno utilizzato una tecnica chiamata prompting — fornire piccoli embedding istruttivi a un modello vision transformer pre-addestrato — per aggirare tali problemi, ma questi approcci presentavano un limite fondamentale: il meccanismo usato per selezionare quale prompt applicare non poteva essere addestrato in modo completamente connesso ed end-to-end insieme al resto del sistema, il che limitava la capacità del modello di assorbire informazioni realmente nuove. Il nuovo sistema del team, chiamato CODA-Prompt, sostituisce il pool fisso di prompt con un insieme di "componenti di prompt" apprendibili che vengono fuse insieme usando pesi basati sull'attenzione e condizionati da ciascuna immagine in input, permettendo di addestrare l'intero sistema end-to-end in un'unica passata di ottimizzazione. Il metodo congela inoltre le componenti apprese in precedenza quando affronta nuovi compiti e applica una penalità matematica per evitare che le componenti interferiscano tra loro. Nei test su benchmark con dataset standard di classificazione di immagini, CODA-Prompt ha superato il precedente metodo di riferimento, DualPrompt, fino a 4,5 punti percentuali di accuratezza media, e ha retto bene anche in un test più realistico che combinava simultaneamente cambiamenti di categoria e variazioni di stile — il tipo di spostamenti di distribuzione composti che rispecchiano le condizioni di impiego nel mondo reale.
abstract
I modelli di visione artificiale soffrono di un fenomeno noto come oblio catastrofico quando apprendono concetti nuovi da dati di addestramento che cambiano continuamente. Le soluzioni tipiche per questo problema di apprendimento continuo richiedono un'ampia ripetizione (rehearsal) dei dati visti in precedenza, il che aumenta i costi di memoria e può violare la privacy dei dati. Di recente, l'emergere di modelli vision transformer pre-addestrati su larga scala ha reso possibili gli approcci basati su prompt come alternativa alla ripetizione dei dati. Questi approcci si basano su un meccanismo key-query per generare i prompt e si sono rivelati altamente resistenti all'oblio catastrofico nel consolidato scenario di apprendimento continuo senza rehearsal. Tuttavia, il meccanismo key di questi metodi non viene addestrato end-to-end insieme alla sequenza di compiti. I nostri esperimenti mostrano che ciò comporta una riduzione della loro plasticità, sacrificando quindi l'accuratezza sui nuovi compiti, e l'incapacità di beneficiare di una maggiore capacità in termini di parametri. Proponiamo invece di apprendere un insieme di componenti di prompt che vengono assemblate con pesi condizionati dall'input per produrre prompt condizionati dall'input, dando luogo a un nuovo schema key-query end-to-end basato sull'attenzione. I nostri esperimenti mostrano che superiamo l'attuale metodo SOTA DualPrompt sui benchmark consolidati fino al 4,5% in accuratezza finale media. Superiamo inoltre lo stato dell'arte fino al 4,4% di accuratezza su un benchmark di apprendimento continuo che contiene sia variazioni di compito di tipo class-incremental sia di tipo domain-incremental, corrispondenti a molti scenari pratici. Il nostro codice è disponibile all'indirizzo https://github.com/GT-RIPL/CODA-Prompt
dettagli
citazione
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}