CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Tóm tắt thông cáo báo chí
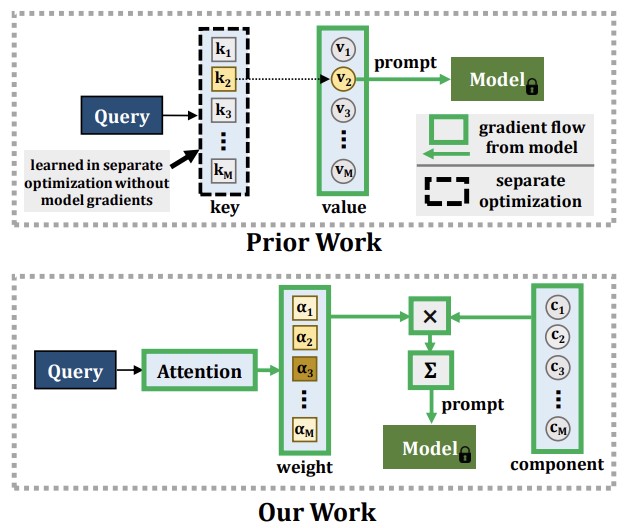
Các nhà nghiên cứu tại Georgia Tech, MIT-IBM Watson AI Lab, Rice University và IBM Research đã phát triển một cách tiếp cận mới cho một vấn đề dai dẳng trong học máy: khi một mô hình AI học những điều mới, nó có xu hướng quên những gì nó đã biết, một hiện tượng được gọi là quên thảm khốc. Các giải pháp tạm thời hiện có thường liên quan đến việc lưu trữ dữ liệu huấn luyện cũ và phát lại nó trong các phiên huấn luyện tương lai, nhưng cách tiếp cận đó làm dấy lên lo ngại về quyền riêng tư và ngốn bộ nhớ. Các phương pháp gần đây hơn sử dụng một kỹ thuật gọi là prompting — đưa các embedding hướng dẫn nhỏ vào một mô hình vision transformer được tiền huấn luyện — để né tránh những vấn đề đó, nhưng các cách tiếp cận đó có một hạn chế cơ bản: cơ chế dùng để chọn prompt nào áp dụng không thể được huấn luyện theo cách kết nối đầy đủ, đầu-cuối cùng với phần còn lại của hệ thống, điều này giới hạn khả năng của mô hình trong việc tiếp thu thông tin thực sự mới. Hệ thống mới của nhóm, gọi là CODA-Prompt, thay thế tập prompt cố định bằng một tập các "thành phần prompt" có thể học được pha trộn với nhau bằng các trọng số dựa trên cơ chế chú ý có điều kiện theo từng ảnh đầu vào, cho phép toàn bộ hệ thống được huấn luyện đầu-cuối trong một lượt tối ưu hóa duy nhất. Phương pháp này cũng đóng băng các thành phần đã học trước đó khi xử lý các tác vụ mới và áp dụng một hình phạt toán học để giữ cho các thành phần không can thiệp lẫn nhau. Trong các thử nghiệm benchmark trên các bộ dữ liệu phân loại ảnh tiêu chuẩn, CODA-Prompt vượt trội hơn phương pháp dẫn đầu trước đó, DualPrompt, tới 4.5 điểm phần trăm về độ chính xác trung bình, và cũng trụ vững tốt trong một thử nghiệm thực tế hơn pha trộn đồng thời cả các thay đổi loại mới lẫn dịch chuyển phong cách — loại dịch chuyển phân phối tổ hợp phản ánh các điều kiện triển khai trong thế giới thực.
tóm tắt
Các mô hình thị giác máy tính chịu một hiện tượng được gọi là quên thảm khốc (catastrophic forgetting) khi học các khái niệm mới từ dữ liệu huấn luyện liên tục thay đổi. Các giải pháp điển hình cho bài toán học liên tục (continual learning) này yêu cầu ôn luyện rộng rãi dữ liệu đã thấy trước đó, điều này làm tăng chi phí bộ nhớ và có thể vi phạm quyền riêng tư dữ liệu. Gần đây, sự xuất hiện của các mô hình vision transformer được tiền huấn luyện quy mô lớn đã cho phép các phương pháp prompting trở thành một giải pháp thay thế cho việc ôn luyện dữ liệu. Các phương pháp này dựa vào một cơ chế khóa-truy vấn (key-query) để tạo ra các prompt và được phát hiện là có khả năng kháng cự rất cao với quên thảm khốc trong thiết lập học liên tục không ôn luyện đã được thiết lập tốt. Tuy nhiên, cơ chế khóa của các phương pháp này không được huấn luyện đầu-cuối với chuỗi tác vụ. Các thí nghiệm của chúng tôi cho thấy điều này dẫn đến giảm tính dẻo (plasticity) của chúng, do đó hy sinh độ chính xác trên tác vụ mới, và không có khả năng hưởng lợi từ việc mở rộng dung lượng tham số. Thay vào đó, chúng tôi đề xuất học một tập các thành phần prompt được lắp ráp với các trọng số có điều kiện theo đầu vào để tạo ra các prompt có điều kiện theo đầu vào, mang lại một sơ đồ khóa-truy vấn đầu-cuối mới dựa trên cơ chế chú ý (attention). Các thí nghiệm của chúng tôi cho thấy chúng tôi vượt trội hơn phương pháp SOTA hiện tại DualPrompt trên các benchmark đã được thiết lập tới 4.5% về độ chính xác cuối cùng trung bình. Chúng tôi cũng vượt trội hơn mức tốt nhất hiện nay tới 4.4% độ chính xác trên một benchmark học liên tục chứa cả các thay đổi tác vụ tăng dần theo lớp (class-incremental) lẫn tăng dần theo miền (domain-incremental), tương ứng với nhiều thiết lập thực tế. Mã của chúng tôi có sẵn tại https://github.com/GT-RIPL/CODA-Prompt
chi tiết
trích dẫn
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}