CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
Résumé du communiqué de presse
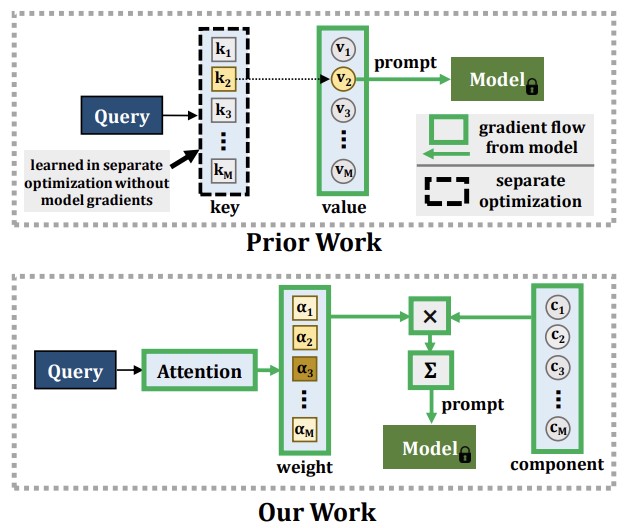
Des chercheurs de Georgia Tech, du MIT-IBM Watson AI Lab, de l'Université Rice et d'IBM Research ont mis au point une nouvelle approche d'un problème persistant en apprentissage automatique : lorsqu'un modèle d'IA apprend de nouvelles choses, il a tendance à oublier ce qu'il savait déjà, un phénomène appelé oubli catastrophique. Les solutions de contournement existantes consistent généralement à stocker d'anciennes données d'entraînement et à les rejouer lors de futures sessions d'entraînement, mais cette approche soulève des préoccupations de confidentialité et consomme de la mémoire. Des méthodes plus récentes ont utilisé une technique appelée prompting — l'injection de petits plongements instructionnels dans un modèle vision transformer pré-entraîné — pour contourner ces problèmes, mais ces approches présentaient une limitation fondamentale : le mécanisme utilisé pour sélectionner l'invite à appliquer ne pouvait pas être entraîné de manière entièrement connectée et de bout en bout en même temps que le reste du système, ce qui plafonnait la capacité du modèle à absorber des informations véritablement nouvelles. Le nouveau système de l'équipe, appelé CODA-Prompt, remplace le réservoir fixe d'invites par un ensemble de « composants d'invite » apprenables, mélangés à l'aide de poids fondés sur l'attention et conditionnés par chaque image en entrée, permettant d'entraîner l'ensemble du système de bout en bout en une seule passe d'optimisation. La méthode fige également les composants précédemment appris lorsqu'elle aborde de nouvelles tâches et applique une pénalité mathématique pour empêcher les composants d'interférer les uns avec les autres. Lors de tests de référence sur des jeux de données standard de classification d'images, CODA-Prompt a surpassé la méthode de pointe précédente, DualPrompt, de jusqu'à 4,5 points de pourcentage en précision moyenne, et s'est également bien comporté sur un test plus réaliste mêlant simultanément des changements de nouvelles catégories et de style — le type de changements de distribution composés qui reflètent les conditions de déploiement réelles.
résumé
Les modèles de vision par ordinateur souffrent d'un phénomène connu sous le nom d'oubli catastrophique lorsqu'ils apprennent de nouveaux concepts à partir de données d'entraînement en évolution continue. Les solutions classiques à ce problème d'apprentissage continu nécessitent une révision extensive des données déjà vues, ce qui augmente les coûts mémoire et peut enfreindre la confidentialité des données. Récemment, l'émergence des modèles vision transformer pré-entraînés à grande échelle a permis des approches par invites (prompting) comme alternative à la révision des données. Ces approches reposent sur un mécanisme clé-requête pour générer les invites et se sont révélées très résistantes à l'oubli catastrophique dans le cadre bien établi de l'apprentissage continu sans révision. Cependant, le mécanisme clé de ces méthodes n'est pas entraîné de bout en bout avec la séquence de tâches. Nos expériences montrent que cela conduit à une réduction de leur plasticité, sacrifiant donc la précision sur les nouvelles tâches, et à une incapacité à tirer parti d'une capacité de paramètres accrue. Nous proposons à la place d'apprendre un ensemble de composants d'invite qui sont assemblés à l'aide de poids conditionnés par l'entrée pour produire des invites conditionnées par l'entrée, donnant lieu à un nouveau schéma clé-requête de bout en bout fondé sur l'attention. Nos expériences montrent que nous surpassons la méthode SOTA actuelle DualPrompt sur des benchmarks établis de jusqu'à 4,5 % en précision finale moyenne. Nous surpassons également l'état de l'art de jusqu'à 4,4 % de précision sur un benchmark d'apprentissage continu qui contient à la fois des changements de tâches incrémentaux par classe et par domaine, correspondant à de nombreux contextes pratiques. Notre code est disponible à l'adresse https://github.com/GT-RIPL/CODA-Prompt
détails
citation
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}