Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
Sintesi del comunicato stampa
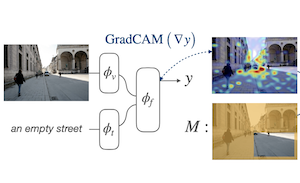
I ricercatori della Rice University e di Adobe Research hanno sviluppato una nuova tecnica di addestramento che migliora il modo in cui i modelli di IA vision-language individuano oggetti e regioni nelle immagini quando viene fornita una descrizione testuale. Il problema che hanno affrontato è che, sebbene i grandi modelli addestrati su coppie immagine-testo su scala di internet possano abbinare in modo approssimativo le parole alle regioni dell'immagine, non vengono esplicitamente istruiti a localizzare le cose con precisione. L'approccio del team, chiamato Attention Mask Consistency (AMC), funziona osservando le "heatmap di spiegazione" basate sul gradiente che un modello produce naturalmente quando decide se un'immagine e un testo corrispondono, e poi penalizzando il modello durante l'addestramento ogni volta che tali heatmap evidenziano le parti sbagliate dell'immagine, ovvero regioni al di fuori delle aree annotate dagli esseri umani. La penalizzazione assume la forma di una margin loss che spinge il modello a concentrare l'energia della heatmap all'interno delle regioni annotate anziché al di fuori di esse. In modo cruciale, il metodo non richiede un rilevatore di oggetti come intermediario, com'è invece il funzionamento della maggior parte degli approcci concorrenti, e può essere applicato sopra un modello esistente — in questo caso ALBEF — senza riaddestramento da zero. Sul benchmark di visual grounding Flickr30k, un modello addestrato con AMC ha raggiunto un'accuratezza dell'86.49%, un miglioramento di oltre cinque punti percentuali rispetto al miglior risultato precedentemente pubblicato con una supervisione comparabile, e ha inoltre stabilito nuovi primati sul dataset di referring expression RefCOCO+. Il lavoro è importante perché offre un percorso relativamente leggero verso un migliore ragionamento spaziale nei modelli vision-language senza richiedere la costosa infrastruttura di un rilevatore di oggetti addestrato.
abstract
Proponiamo una loss basata sul margine per il tuning di modelli vision-language congiunti, in modo che le loro spiegazioni basate sul gradiente siano coerenti con le annotazioni a livello di regione fornite dagli esseri umani per dataset di grounding relativamente più piccoli. Ci riferiamo a questo obiettivo come Attention Mask Consistency (AMC) e dimostriamo che produce risultati di visual grounding superiori rispetto ai metodi precedenti che si basano sull'uso di modelli vision-language per assegnare un punteggio agli output di rilevatori di oggetti. In particolare, un modello addestrato con AMC sopra gli obiettivi standard di modellazione vision-language ottiene un'accuratezza allo stato dell'arte dell'86.49% nel benchmark di visual grounding Flickr30k, un miglioramento assoluto del 5.38% rispetto al miglior modello precedente addestrato con lo stesso livello di supervisione. Il nostro approccio si comporta inoltre eccezionalmente bene su benchmark consolidati per la referring expression comprehension, dove ottiene un'accuratezza dell'80.34% nel test facile di RefCOCO+ e del 64.55% nello split difficile. AMC è efficace, facile da implementare ed è generale, in quanto può essere adottato da qualsiasi modello vision-language e può utilizzare qualsiasi tipo di annotazione di regione.
dettagli
citazione
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}