One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
News Release Summary
Researchers from Rice University and Snap Inc. have developed a technique called ELIT, short for Elastic Latent Interface Transformer, that gives image and video generation models the ability to trade off computation speed against output quality on the fly — without retraining the model for each desired operating point. The core problem they addressed is that standard diffusion transformer models burn the same amount of computation on every patch of an image regardless of whether that patch contains intricate detail or blank sky, and they are locked to a fixed computational cost tied to image resolution. To fix this, the team inserted a small set of learnable "latent tokens" between the model's early and late processing stages, connected by two lightweight cross-attention layers they call Read and Write. During training, the model randomly drops some of those latent tokens, which forces it to pack the most important information into the tokens it keeps most often, producing a naturally ordered representation. At inference time, a user can simply choose how many latent tokens to use, directly dialing compute up or down. Tested across several popular architectures including DiT, U-ViT, HDiT, and the 20-billion-parameter Qwen-Image model, ELIT consistently improved image quality metrics — cutting FID scores by as much as 53% on 512-pixel ImageNet benchmarks — while also letting users cut computation by roughly 35% to 65% with only modest quality loss. The approach also unlocks a cheaper form of classifier-free guidance by using the low-token version of the same model as a built-in "weak" reference, reducing guidance costs by about a third.
abstract
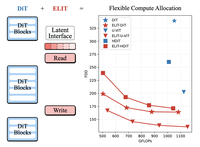
Diffusion transformers (DiTs) achieve high generative quality but lock FLOPs to image resolution, limiting principled latency-quality trade-offs, and allocate computation uniformly across input spatial tokens, wasting resource allocation to unimportant regions. We introduce Elastic Latent Interface Transformer (ELIT), a drop-in, DiT-compatible mechanism that decouples input image size from compute. Our approach inserts a latent interface, a learnable variable-length token sequence on which standard transformer blocks can operate. Lightweight Read and Write cross-attention layers move information between spatial tokens and latents and prioritize important input regions. By training with random dropping of tail latents, ELIT learns to produce importance-ordered representations with earlier latents capturing global structure while later ones contain information to refine details. At inference, the number of latents can be dynamically adjusted to match compute constraints. ELIT is deliberately minimal, adding two cross-attention layers while leaving the rectified flow objective and the DiT stack unchanged. Across datasets and architectures (DiT, U-ViT, HDiT, MM-DiT), ELIT delivers consistent gains. On ImageNet-1K 512px, ELIT delivers an average gain of $35.3\%$ and $39.6\%$ in FID and FDD scores. Project page: https://snap-research.github.io/elit/
details
citation
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is ELIT and what problem does it address? ELIT is a drop-in latent-interface mechanism for diffusion transformers that decouples compute from image resolution and lets one generative model operate across multiple quality and latency budgets.
- How does ELIT change a diffusion transformer? It inserts a variable-length set of latent tokens between a short spatial head and tail, using lightweight Read and Write cross-attention layers to move information between image tokens and the latent interface.
- How does ELIT provide flexible inference budgets? During training, tail latent tokens are randomly dropped so earlier tokens learn the most important information, and at inference users choose how many latent tokens to keep to control FLOPs.
- What empirical gains does ELIT report? On ImageNet-1K 512px, ELIT improves FID and FDD substantially across DiT, U-ViT, and HDiT backbones, including up to 53 percent FID improvement for the DiT setting reported in the paper.
- Does ELIT scale to large generation models? Yes, the paper applies ELIT to Qwen-Image, a 20B MM-DiT model, and shows a smooth compute-quality tradeoff with up to roughly 2.7x speedup while maintaining strong DPG-Bench scores.
Main contributions
- The paper introduces a minimal Read/Write latent interface that keeps the rectified-flow objective and the main DiT stack unchanged, making ELIT easy to graft onto existing diffusion transformer families.
- ELIT demonstrates adaptive computation by using the Read layer to pull informative spatial regions into the latent interface rather than spending equal compute on easy or padded regions.
- The multi-budget training strategy creates an importance-ordered latent sequence, allowing a single set of weights to support many inference budgets without retraining.
- Experiments show consistent image-generation improvements across DiT, U-ViT, and HDiT, favorable video-generation results on Kinetics-700, and compatibility with training-free acceleration methods such as TeaCache.
- ELIT enables cheap guidance and autoguidance by using lower-budget versions of the same model as weak references, reducing guidance cost while improving sample quality.
Limitations and cautions
- ELIT adds Read and Write layers plus latent-token scheduling, so it is a small architectural change rather than a purely training-free acceleration method; the drop-in design and broad backbone results make that added complexity well justified.
- The Qwen-Image experiment fine-tunes a large existing model with available real and synthetic data rather than reproducing the original model's full proprietary training pipeline, but it still provides valuable evidence that ELIT scales to 20B-parameter MM-DiT systems.
- The lowest-budget Qwen-Image settings trade some benchmark quality for speed, which is expected for an elastic model and useful because users can choose the budget that fits their latency and quality needs.
- Most detailed ablations are on class-conditional ImageNet and Kinetics settings, leaving text-to-image deployment details and user-facing quality preferences as natural future evaluation directions.
- The method improves compute allocation inside DiT-like generators rather than replacing all other efficiency techniques, and the compatibility with TeaCache and guidance strategies suggests it can be combined productively with complementary accelerators.
How to read this result
This paper is best read as a strong systems-and-modeling contribution for diffusion transformers: ELIT gives one model practical control over compute budgets, improves generation quality across several backbones, and scales the idea to large modern image generators while keeping the core architecture changes compact.