ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
News Release Summary
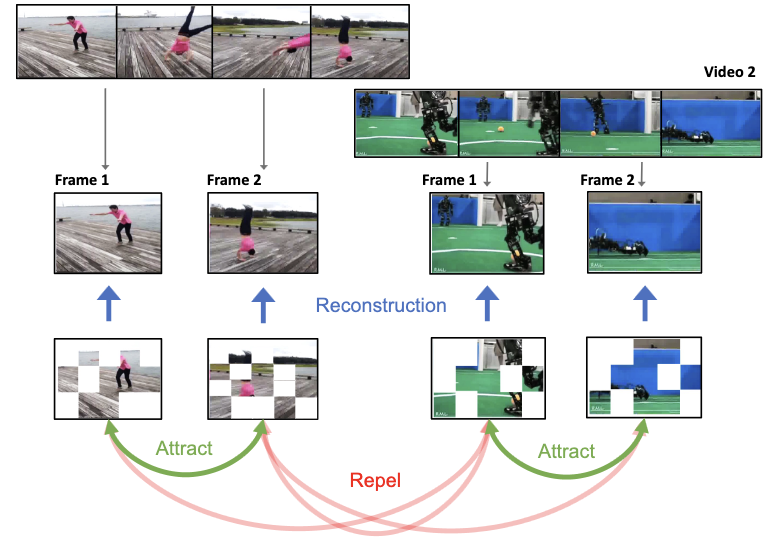
Researchers at Rice University and Google DeepMind have developed a self-supervised visual learning system called ViC-MAE that trains a single AI model to understand both still images and video without requiring labeled data. The core challenge they addressed is that existing models tend to be good at one modality or the other, but not both — and in particular, models trained on video have historically struggled when asked to perform well on image tasks. Their approach combines two existing techniques: masked autoencoders, which train a model to reconstruct randomly hidden patches of an image, and contrastive learning, which trains a model to recognize that two different views of the same scene should produce similar representations. The novel twist is that instead of artificially converting images into fake videos by repeating frames — a common workaround — ViC-MAE treats frames sampled a second or so apart within a real video as natural "augmented views" of the same scene, feeding those temporal variations into the contrastive learning objective while still reconstructing individual frames with the masking loss. The team also found that pooling local patch features into a global representation, rather than relying on a single classification token, helped prevent the model from collapsing during training. Tested on standard benchmarks, the ViT-Large version of ViC-MAE reached 87.1% top-1 accuracy on ImageNet and 75.9% on the challenging Something-Something-v2 video benchmark, outperforming the comparable self-supervised method OmniMAE by roughly 2.4 percentage points on ImageNet while also beating it on video tasks — a result that suggests video data, used thoughtfully, can meaningfully strengthen image understanding without sacrificing video performance.
abstract
We propose ViC-MAE, a model that combines both Masked AutoEncoders (MAE) and contrastive learning. ViC-MAE is trained using a global featured obtained by pooling the local representations learned under an MAE reconstruction loss and leveraging this representation under a contrastive objective across images and video frames. We show that visual representations learned under ViC-MAE generalize well to both video and image classification tasks. Particularly, ViC-MAE obtains state-of-the-art transfer learning performance from video to images on Imagenet-1k compared to the recently proposed OmniMAE by achieving a top-1 accuracy of 86% (+1.3% absolute improvement) when trained on the same data and 87.1% (+2.4% absolute improvement) when training on extra data. At the same time ViC-MAE outperforms most other methods on video benchmarks by obtaining 75.9% top-1 accuracy on the challenging Something something-v2 video benchmark . When training on videos and images from a diverse combination of datasets, our method maintains a balanced transfer-learning performance between video and image classification benchmarks, coming only as a close second to the best supervised method.
details
citation
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is ViC-MAE? ViC-MAE is a self-supervised visual representation learning method that combines masked autoencoding with contrastive learning so one backbone can learn useful features for both images and videos.
- How does ViC-MAE use video differently from prior image-video pretraining methods? Instead of converting images into repeated-frame videos, ViC-MAE treats nearby frames from real videos as natural temporal augmentations and aligns their pooled representations.
- Why combine masked image modeling and contrastive learning? The reconstruction objective encourages strong local patch features, while the contrastive objective encourages global invariance across augmented images and temporally shifted video frames.
- What role does pooling play in the method? ViC-MAE pools local ViT features into a global representation before the contrastive branch, which the paper shows is important for stable training and avoids relying only on a classification token.
- What evidence shows that ViC-MAE learns balanced image and video representations? The paper reports strong transfer to ImageNet, Kinetics-400, Places365, Something-Something-v2, several downstream image classification datasets, and COCO detection and segmentation.
Main contributions
- The paper introduces a unified self-supervised framework that trains from both images and videos using a combination of masked reconstruction and contrastive alignment.
- ViC-MAE shows that video frames can serve as effective temporal augmentations for image-level representation learning, improving video-to-image transfer without giving up video performance.
- The method identifies global pooling over local MAE features as a practical design choice for stable contrastive masked autoencoder training.
- With a ViT-Large backbone, ViC-MAE reaches 87.1% ImageNet top-1 accuracy and 75.9% Something-Something-v2 top-1 accuracy, outperforming comparable self-supervised baselines such as OmniMAE in the reported settings.
- The paper provides broad empirical validation across image classification, video action recognition, object detection, and segmentation, making the contribution useful beyond a single benchmark.
Limitations and cautions
- The strongest results use large ViT backbones and multi-dataset pretraining, which is typical for modern foundation-style visual representation learning and helps show the method's scaling behavior.
- ViC-MAE is primarily evaluated through transfer and fine-tuning benchmarks rather than every possible downstream video or image task, leaving additional domains as promising follow-up evaluations.
- The approach depends on a careful balance between reconstruction and contrastive objectives, but the paper includes ablations on pooling, frame separation, augmentations, and data mix that make the design choices clear.
- The method improves unified image-video self-supervision, while task-specific supervised models can still be competitive on some individual benchmarks; this frames ViC-MAE as a strong general representation learner rather than a narrow specialist.
- The paper focuses on visual-only pretraining, so extensions to text, audio, or broader multimodal alignment remain natural opportunities building on the same framework.
How to read this result
This paper is best read as a strong and practical advance in self-supervised image-video representation learning: ViC-MAE demonstrates that video data can improve image representations while preserving excellent video performance, and it does so with a clean combination of masked autoencoding, temporal contrastive learning, and pooled local features.