ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
News Release Summary
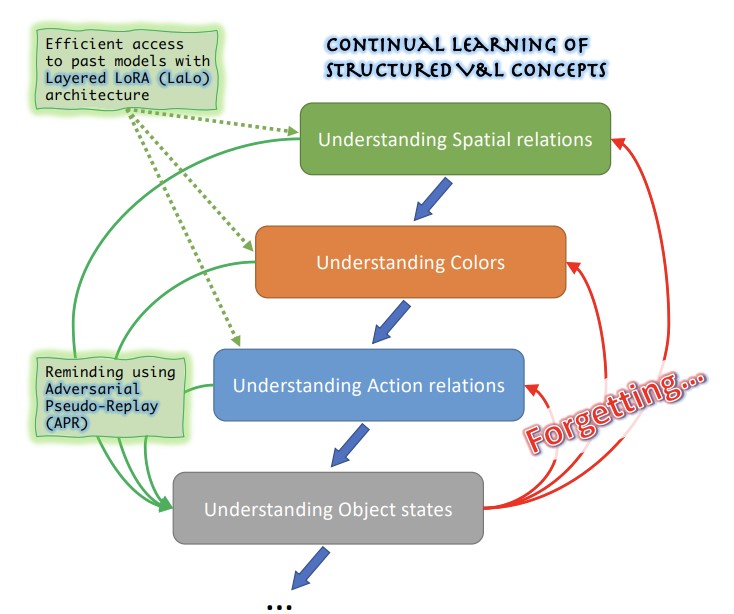
Researchers from MIT-IBM Watson AI Lab, Georgia Tech, Rice University, IBM Research, and Stanford have tackled a practical but underexplored problem with large vision-and-language AI models: these systems tend to struggle with understanding nuanced relational and descriptive concepts — such as object colors, sizes, spatial positions, and states — and when engineers try to fix one such weakness by fine-tuning the model on new data, the model tends to forget how to handle previously corrected weaknesses, a phenomenon known as catastrophic forgetting. The situation is made harder by the fact that the data used to identify and fix each problem is often private and cannot be retained or reused across training rounds. To address this, the team created ConStruct-VL, the first benchmark specifically designed to evaluate continual learning of these structured visual-language concepts without access to previous task data and without any hint at test time about which type of concept is being evaluated. They also developed two complementary technical contributions: a Layered-LoRA (LaLo) architecture that stacks lightweight, low-rank adapter modules on top of a frozen base model for each new task, allowing the system to efficiently access any prior task's model during training without reloading weights; and an Adversarial Pseudo-Replay (APR) method that uses those past models to generate tricky negative training examples — for instance, subtly altering a text description to include a color word inconsistent with the paired image — which are then used to remind the current model what it previously learned. Tested on the BLIP vision-language model across multiple task sequences drawn from the Visual Genome and Visual Attributes in the Wild datasets, the combined approach reduced average forgetting by roughly five times and improved final accuracy by up to 6.8 percentage points compared to the best competing data-free continual learning methods, while using only about 2.8 percent of the full model's parameters — results that matter because they suggest a viable path for continuously patching AI models in privacy-sensitive real-world deployments without degrading earlier improvements.
abstract
Recently, large-scale pre-trained Vision-and-Language (VL) foundation models have demonstrated remarkable capabilities in many zero-shot downstream tasks, achieving competitive results for recognizing objects defined by as little as short text prompts. However, it has also been shown that VL models are still brittle in Structured VL Concept (SVLC) reasoning, such as the ability to recognize object attributes, states, and inter-object relations. This leads to reasoning mistakes, which need to be corrected as they occur by teaching VL models the missing SVLC skills; often this must be done using private data where the issue was found, which naturally leads to a data-free continual (no task-id) VL learning setting. In this work, we introduce the first Continual Data-Free Structured VL Concepts Learning (ConStruct-VL) benchmark and show it is challenging for many existing data-free CL strategies. We, therefore, propose a data-free method comprised of a new approach of Adversarial Pseudo-Replay (APR) which generates adversarial reminders of past tasks from past task models. To use this method efficiently, we also propose a continual parameter-efficient Layered-LoRA (LaLo) neural architecture allowing no-memory-cost access to all past models at train time. We show this approach outperforms all data-free methods by as much as ~7% while even matching some levels of experience-replay (prohibitive for applications where data-privacy must be preserved). Our code is publicly available at https://github.com/jamessealesmith/ConStruct-VL
details
citation
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}