Where and Who? Automatic Semantic-Aware Person Composition
News Release Summary
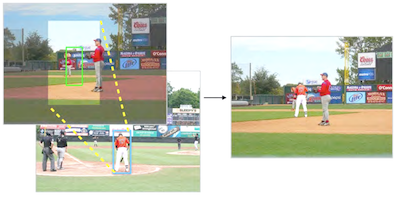
Researchers at the University of Virginia have built a system that can automatically drop a realistic-looking human figure into a photograph without any human guidance on where to put them or who to use. Most existing photo compositing tools handle the technical work of blending edges and matching colors, but still leave it to the user to pick a foreground subject, choose where to place it, and decide how big it should be. The new system tackles those judgment calls computationally by training a branching convolutional neural network on tens of thousands of annotated images from the MS-COCO dataset, teaching it to predict plausible locations and sizes for a person given only the background scene. Once a bounding box is predicted, the system searches a pool of roughly 4,100 manually segmented person cutouts, using deep features from a pretrained ResNet50 model to match both the overall scene type and the immediate local surroundings before blending the chosen figure in with alpha matting. In a crowd-sourced user study on Amazon Mechanical Turk, human judges rated the system's composites as real about 44 percent of the time, compared to roughly 18 to 28 percent for three baseline approaches, though real photographs still scored around 90 percent. The gap narrows considerably when texture and lighting are stripped away, suggesting that color and illumination mismatches — not placement or figure selection — are the main remaining hurdle. The researchers say the work represents an early step toward tools that could assist graphic designers, filmmakers, and storyboard artists who currently spend considerable time manually assembling such scenes.
abstract
Image compositing is a method used to generate realistic yet fake imagery by inserting contents from one image to another. Previous work in compositing has focused on improving appearance compatibility of a user selected foreground segment and a background image (i.e. color and illumination consistency). In this work, we instead develop a fully automated compositing model that additionally learns to select and transform compatible foreground segments from a large collection given only an input image background. To simplify the task, we restrict our problem by focusing on human instance composition, because human segments exhibit strong correlations with their background and because of the availability of large annotated data. We develop a novel branching Convolutional Neural Network (CNN) that jointly predicts candidate person locations given a background image. We then use pre-trained deep feature representations to retrieve person instances from a large segment database. Experimental results show that our model can generate composite images that look visually convincing. We also develop a user interface to demonstrate the potential application of our method.
details
citation
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}