SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
News Release Summary
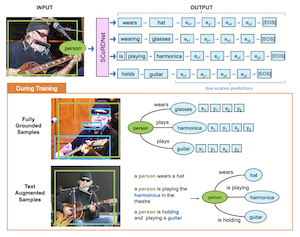
Researchers from Rice University and Adobe Research have developed a system called SCoRD — short for Subject-Conditional Relation Detection — that, given a specific object in a photo, automatically identifies everything that object is interacting with, what those interactions are, and where the other objects are located in the image. Rather than trying to map every possible relationship between every object in a scene, which quickly becomes impractical, the system focuses on a single chosen subject and exhaustively catalogs only its relevant connections. The team built their model, SCoRDNet, as an auto-regressive sequence decoder that outputs relation-object pairs alongside bounding box coordinates as a stream of tokens, and they designed a benchmark based on the Open Images dataset specifically crafted so that training and testing data have mismatched relationship statistics — making it harder for a model to simply memorize common patterns. A key finding is that the system's performance on rare or previously unseen relationship types improved substantially when training was supplemented with noisy relationship triplets automatically extracted from image captions, even when those captions came with no bounding box annotations at all. On relationships the base model had never encountered during training, the text-augmented version achieved a recall of 33.8% for relation-object pairs and 26.75% for their box locations, compared to near-zero for the unaided baseline. The work matters because it offers a more scalable path toward open-vocabulary relationship detection: rather than requiring expensive fully annotated datasets for every possible interaction, the approach suggests that large collections of captioned images already on the internet could dramatically expand what such systems can recognize and localize.
abstract
We propose Subject-Conditional Relation Detection SCoRD, where conditioned on an input subject, the goal is to predict all its relations to other objects in a scene along with their locations. Based on the Open Images dataset, we propose a challenging OIv6-SCoRD benchmark such that the training and testing splits have a distribution shift in terms of the occurrence statistics of $\langle$subject, relation, object$\rangle$ triplets. To solve this problem, we propose an auto-regressive model that given a subject, it predicts its relations, objects, and object locations by casting this output as a sequence of tokens. First, we show that previous scene-graph prediction methods fail to produce as exhaustive an enumeration of relation-object pairs when conditioned on a subject on this benchmark. Particularly, we obtain a recall@3 of 83.8% for our relation-object predictions compared to the 49.75% obtained by a recent scene graph detector. Then, we show improved generalization on both relation-object and object-box predictions by leveraging during training relation-object pairs obtained automatically from textual captions and for which no object-box annotations are available. Particularly, for $\langle$subject, relation, object$\rangle$ triplets for which no object locations are available during training, we are able to obtain a recall@3 of 33.80% for relation-object pairs and 26.75% for their box locations.
details
citation
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is SCoRD? SCoRD is a subject-conditional relation detection task where a model receives a chosen subject in an image and predicts that subject's relations, related objects, and object locations.
- How is SCoRD different from full scene graph generation? Instead of predicting every relation among every object, SCoRD focuses on exhaustively describing the relations of one queried subject, which is often more practical for downstream applications.
- What is SCoRDNet? SCoRDNet is an autoregressive vision-language model that represents relation-object predictions and bounding box coordinates as a sequence of tokens.
- Why use text-augmented data? Caption-derived relation-object triplets provide scalable supervision for rare or unseen relations, even when the captions do not include object box annotations.
- What does the OIv6-SCoRD benchmark test? The benchmark creates train-test distribution shifts in subject-relation-object triplets, making it a strong test of generalization beyond memorized relation statistics.
Main contributions
- The paper defines Subject-Conditional Relation Detection as a focused alternative to full scene graph generation for describing the relationships of a specified object.
- It introduces OIv6-SCoRD, a benchmark designed to stress-test relation detection under distribution shifts in relation-object statistics.
- SCoRDNet casts relation, object, and localization prediction as a unified token decoding problem, allowing grounded and ungrounded supervision to be handled in one model.
- The paper shows that text-augmented training from captions substantially improves generalization to underrepresented and unseen relation-object pairs.
- SCoRDNet outperforms subject-conditioned adaptations of scene graph methods on relation-object prediction and demonstrates that ungrounded captions can improve both relation prediction and object localization.
Limitations and cautions
- SCoRD assumes a subject and its box are provided as input, which keeps the task focused and makes it well suited for applications where a user or upstream detector identifies the object of interest.
- Caption-derived relation triplets are noisy and often lack object boxes, but the paper turns this weak signal into a strength by showing that it still improves generalization when combined with grounded data.
- The method is evaluated on a benchmark derived from Open Images and caption sources such as COCO and Conceptual Captions, leaving broader open-world image collections as natural next tests.
- SCoRDNet predicts boxes through sequence decoding rather than specialized box refinement, which leaves room for future combinations with stronger localization modules.
- The task focuses on subject-centered relations rather than complete scene graphs, giving a practical and scalable formulation while complementing broader graph-generation systems.
How to read this result
This paper is best read as a strong step toward scalable visual relationship understanding: SCoRD reframes relation detection around a queried subject, and SCoRDNet shows that inexpensive caption supervision can meaningfully expand what relation-object pairs a model can recognize and localize.