CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning
プレスリリース要約
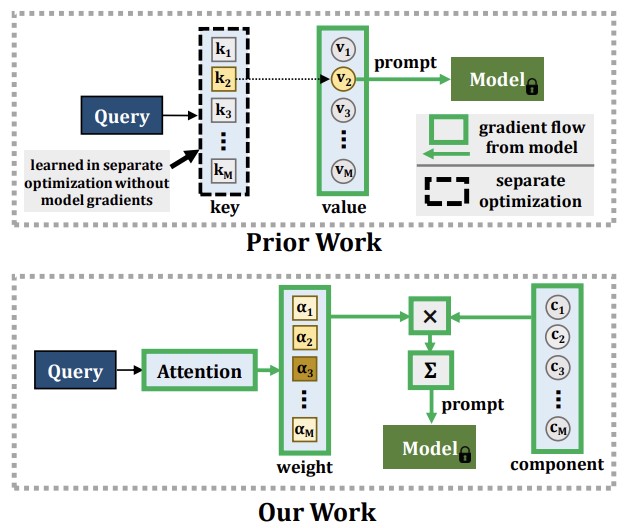
Georgia Tech、MIT-IBM Watson AI Lab、Rice University、IBM Researchの研究者らは、機械学習における根強い問題に対する新たなアプローチを開発しました。その問題とは、AIモデルが新しいことを学ぶと、すでに知っていたことを忘れてしまう傾向があるというもので、破滅的忘却と呼ばれる現象です。既存の回避策は、典型的には古い学習データを保存し、将来の学習セッション中にそれをリプレイするというものですが、このアプローチはプライバシー上の懸念を生み、メモリを大量に消費します。より新しい手法では、プロンプティングと呼ばれる技術、すなわち事前学習済みのVision Transformerモデルに小さな指示的埋め込みを与える技術を用いてこれらの問題を回避していましたが、これらのアプローチには根本的な限界がありました。どのプロンプトを適用するかを選択するために用いられる機構を、システムの残りの部分と並んで完全に結合したエンドツーエンドの方法で学習できなかったのです。これにより、真に新しい情報を吸収するモデルの能力が頭打ちになっていました。研究チームの新しいシステムはCODA-Promptと呼ばれ、固定されたプロンプトのプールを、入力画像ごとに条件付けられた注意機構に基づく重みで混ぜ合わせる、学習可能な「プロンプトコンポーネント」の集合に置き換えます。これにより、システム全体を単一の最適化パスでエンドツーエンドに学習できます。この手法はまた、新しいタスクに取り組む際に以前学習したコンポーネントを凍結し、コンポーネントどうしが干渉しないように数学的なペナルティを適用します。標準的な画像分類データセットでのベンチマークテストにおいて、CODA-Promptは従来の主要手法であるDualPromptを平均精度で最大4.5パーセントポイント上回り、新カテゴリの変化とスタイルの変化を同時に混ぜたより現実的なテスト、すなわち現実世界の運用条件を反映する複合的な分布シフトに対してもよく持ちこたえました。
要旨
コンピュータビジョンモデルは、絶えず変化する学習データから新しい概念を学習する際に、破滅的忘却として知られる現象に悩まされます。この継続学習問題に対する典型的な解決策は、過去に見たデータの大規模なリハーサルを必要とし、メモリコストを増大させ、データプライバシーを侵害するおそれがあります。近年、大規模に事前学習されたVision Transformerモデルの登場により、データリハーサルの代替としてプロンプティング手法が可能になりました。これらの手法は、プロンプトを生成するためにキー・クエリ機構に依存しており、確立されたリハーサル不要の継続学習設定において破滅的忘却に対して非常に頑健であることが分かっています。しかし、これらの手法のキー機構はタスク系列とともにエンドツーエンドで学習されていません。我々の実験は、これが可塑性の低下につながり、その結果として新タスクの精度が犠牲になり、拡張されたパラメータ容量の恩恵を受けられなくなることを示しています。我々は代わりに、入力に条件付けられた重みで組み立てて入力条件付きのプロンプトを生成する一連のプロンプトコンポーネントを学習することを提案し、その結果、注意機構に基づく新たなエンドツーエンドのキー・クエリ方式を実現します。我々の実験は、確立されたベンチマークにおいて、現行のSOTA手法であるDualPromptを平均最終精度で最大4.5%上回ることを示しています。また、多くの実用的な設定に対応する、クラス増分とドメイン増分の両方のタスク変化を含む継続学習ベンチマークにおいても、最先端を最大4.4%の精度で上回ります。我々のコードはhttps://github.com/GT-RIPL/CODA-Prompt で公開されています。
詳細
引用
@inproceedings{smith2023coda,
title = {CODA-Prompt: COntinual Decomposed Attention-based Prompting for Rehearsal-Free Continual Learning},
author = {Smith, James Seale and Karlinsky, Leonid and Gutta, Vyshnavi and Cascante-Bonilla, Paola and Kim, Donghyun and Arbelle, Assaf and Panda, Rameswar and Feris, Rogerio and Kira, Zsolt},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.13218},
}