Improving Progressive Generation with Decomposable Flow Matching
News Release Summary
Researchers from Rice University and Snap Inc. have developed a new approach to generating high-resolution images and videos that improves quality without the complexity typically associated with multi-stage generative systems. The work, called Decomposable Flow Matching (DFM), addresses a known challenge in AI image synthesis: generating fine visual detail efficiently requires breaking the task into coarser-to-finer steps, but existing methods for doing so usually demand separate models for each stage, custom diffusion processes, or elaborate handoffs between stages. DFM sidesteps these complications by applying a standard technique called Flow Matching independently to each level of a multiscale image representation — essentially a Laplacian pyramid that separates an image into layers of increasing detail — while using a single shared model throughout. During training, the system simulates the progressive generation process by sampling different noise levels for each stage, and at inference time a simple scheduler moves through the stages sequentially from coarse to fine. Tested on the standard ImageNet-1K benchmark at 512-pixel resolution, DFM reduced a key quality metric called FDD by 35% compared to plain Flow Matching and by 26% over the best competing multi-stage method, using the same amount of training compute. The researchers also applied DFM to fine-tuning FLUX, a large commercial-grade image generation model, and found it converged to the target image distribution faster than standard fine-tuning, cutting FID scores by roughly 29%. The significance of the work lies mainly in its simplicity: it delivers meaningful quality gains through a minimal modification to an existing training pipeline rather than requiring an entirely new architecture or separate model cascade.
abstract
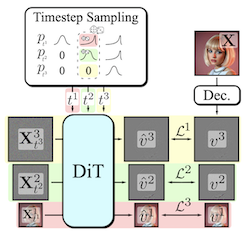
Generating high-dimensional visual modalities is a computationally intensive task. A common solution is progressive generation, where the outputs are synthesized in a coarse-to-fine spectral autoregressive manner. While diffusion models benefit from the coarse-to-fine nature of denoising, explicit multi-stage architectures are rarely adopted. These architectures have increased the complexity of the overall approach, introducing the need for a custom diffusion formulation, decomposition-dependent stage transitions, add-hoc samplers, or a model cascade. Our contribution, Decomposable Flow Matching (DFM), is a simple and effective framework for the progressive generation of visual media. DFM applies Flow Matching independently at each level of a user-defined multi-scale representation (such as Laplacian pyramid). As shown by our experiments, our approach improves visual quality for both images and videos, featuring superior results compared to prior multistage frameworks. On Imagenet-1k 512px, DFM achieves 35.2% improvements in FDD scores over the base architecture and 26.4% over the best-performing baseline, under the same training compute. When applied to finetuning of large models, such as FLUX, DFM shows faster convergence speed to the training distribution. Crucially, all these advantages are achieved with a single model, architectural simplicity, and minimal modifications to existing training pipelines.
details
citation
@inproceedings{hajiali2025improving,
title = {Improving Progressive Generation with Decomposable Flow Matching},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Sahni, Arpit and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2025},
booktitle = {Conf on Neural Information Processing Systems. NeurIPS 2025},
url = {https://arxiv.org/abs/2506.19839},
}
automatically generated questions, main contributions and limitations of this paper
Questions this paper helps answer
- What is Decomposable Flow Matching and what problem does it address? DFM is a progressive generation framework that applies Flow Matching independently across levels of a multiscale representation, improving coarse-to-fine image and video synthesis without requiring model cascades or custom diffusion processes.
- How does DFM generate samples progressively? It decomposes visual data into stages such as a Laplacian pyramid, assigns each stage its own flow timestep, and uses a sampler that advances stages from coarse structure to fine detail.
- Why is DFM simpler than many prior progressive generation methods? It keeps a single shared model and a standard Flow Matching formulation, avoiding separate per-stage models, specialized samplers, and complicated transition mechanisms.
- How does DFM perform on image generation benchmarks? On ImageNet-1K at 512px and 1024px, DFM outperforms Flow Matching, cascaded baselines, and Pyramidal Flow across the main metrics and guidance settings reported in the paper.
- Does DFM help large-scale model fine-tuning? Yes, when applied to FLUX fine-tuning, DFM reaches better FID, FDD, and CLIP similarity than standard fine-tuning under the same training compute, showing faster convergence to the target distribution.
Main contributions
- The paper introduces a simple multiscale extension of Flow Matching that turns visual generation into a decomposable coarse-to-fine process while keeping one shared generator.
- DFM supports user-defined decompositions, with the paper using Laplacian pyramids while noting that wavelet, DCT, Fourier, or multiscale autoencoder decompositions are natural alternatives.
- The method includes a detailed analysis of training timestep distributions, sampling thresholds, per-stage sampling steps, masking, decomposition choices, and compute allocation strategies.
- Experiments show strong results on ImageNet-1K image generation and Kinetics-700 video generation, including the best reported values among the paper's progressive-generation baselines in most settings.
- The FLUX fine-tuning experiment demonstrates that DFM can improve adaptation of a large generative model with minimal changes to the training pipeline.
Limitations and cautions
- DFM introduces additional training and sampling hyperparameters, but the paper provides extensive ablations and practical guidance showing that stable settings transfer across multiple experiments.
- The framework's performance depends on balancing low-frequency structure and high-frequency detail, so future work can refine automatic scheduling policies; the current results already show that this balance can produce large quality gains.
- The main implementation uses Laplacian decompositions, leaving other decompositions such as DCT, wavelets, and multiscale autoencoders as promising extensions rather than weaknesses of the core formulation.
- The large-model experiment focuses on fine-tuning FLUX to a target distribution rather than claiming to improve the original frontier model in every deployment setting, which keeps the conclusion well scoped and still practically valuable.
- DFM is best viewed as a training-time framework for better progressive generation rather than a standalone inference-only accelerator, and its simplicity makes it complementary to future systems work on faster sampling and deployment.
How to read this result
This paper is best read as a strong and elegant contribution to progressive visual generation: DFM captures the benefits of coarse-to-fine synthesis with a single Flow Matching model, improves image and video quality across benchmarks, and offers a practical path for better fine-tuning of large generative systems.