Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations
News Release Summary
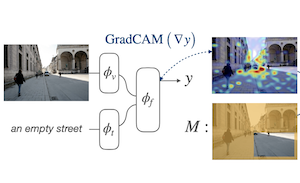
Researchers from Rice University and Adobe Research have developed a new training technique that improves how AI vision-language models pinpoint objects and regions in images when given a text description. The problem they tackled is that while large models trained on internet-scale image-text pairs can loosely match words to image regions, they aren't explicitly taught to localize things precisely. The team's approach, called Attention Mask Consistency (AMC), works by looking at the gradient-based "explanation heatmaps" a model naturally produces when deciding whether an image and text match, and then penalizing the model during training whenever those heatmaps highlight the wrong parts of the image — that is, regions outside of human-annotated areas. The penalty takes the form of a margin loss that pushes the model to concentrate heatmap energy inside annotated regions rather than outside them. Crucially, the method doesn't require an object detector as a middleman, which is how most competing approaches work, and it can be layered on top of an existing model — in this case ALBEF — without retraining from scratch. On the Flickr30k visual grounding benchmark, a model trained with AMC reached 86.49% accuracy, an improvement of more than five percentage points over the best previously published result under comparable supervision, and it also set new marks on the RefCOCO+ referring expression dataset. The work matters because it offers a relatively lightweight path to better spatial reasoning in vision-language models without requiring the expensive infrastructure of a trained object detector.
abstract
We propose a margin-based loss for tuning joint vision-language models so that their gradient-based explanations are consistent with region-level annotations provided by humans for relatively smaller grounding datasets. We refer to this objective as Attention Mask Consistency (AMC) and demonstrate that it produces superior visual grounding results than previous methods that rely on using vision-language models to score the outputs of object detectors. Particularly, a model trained with AMC on top of standard vision-language modeling objectives obtains a state-of-the-art accuracy of 86.49% in the Flickr30k visual grounding benchmark, an absolute improvement of 5.38% when compared to the best previous model trained under the same level of supervision. Our approach also performs exceedingly well on established benchmarks for referring expression comprehension where it obtains 80.34% accuracy in the easy test of RefCOCO+, and 64.55% in the difficult split. AMC is effective, easy to implement, and is general as it can be adopted by any vision-language model, and can use any type of region annotations.
details
citation
@inproceedings{yang2023improving,
title = {Improving Visual Grounding by Encouraging Consistent Gradient-based Explanations},
author = {Yang, Ziyan and Kafle, Kushal and Dernoncourt, Franck and Ordonez, Vicente},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2206.15462},
}